你已经是一个成熟的爬虫了,应该学会自己去对抗反爬码农了🙊-『爬虫进阶指南』
update 19.5.7 QA 一下http://www.66ip.cn/ 首次进入的 js 逆向思路 update 19.4.21 更新了一篇关于 js 逆向的文章 究竟是道德的沦丧,还是现实的骨感,让携程反爬工程师在代码里写下这句话-『爬虫进阶第二弹』
QA 环节
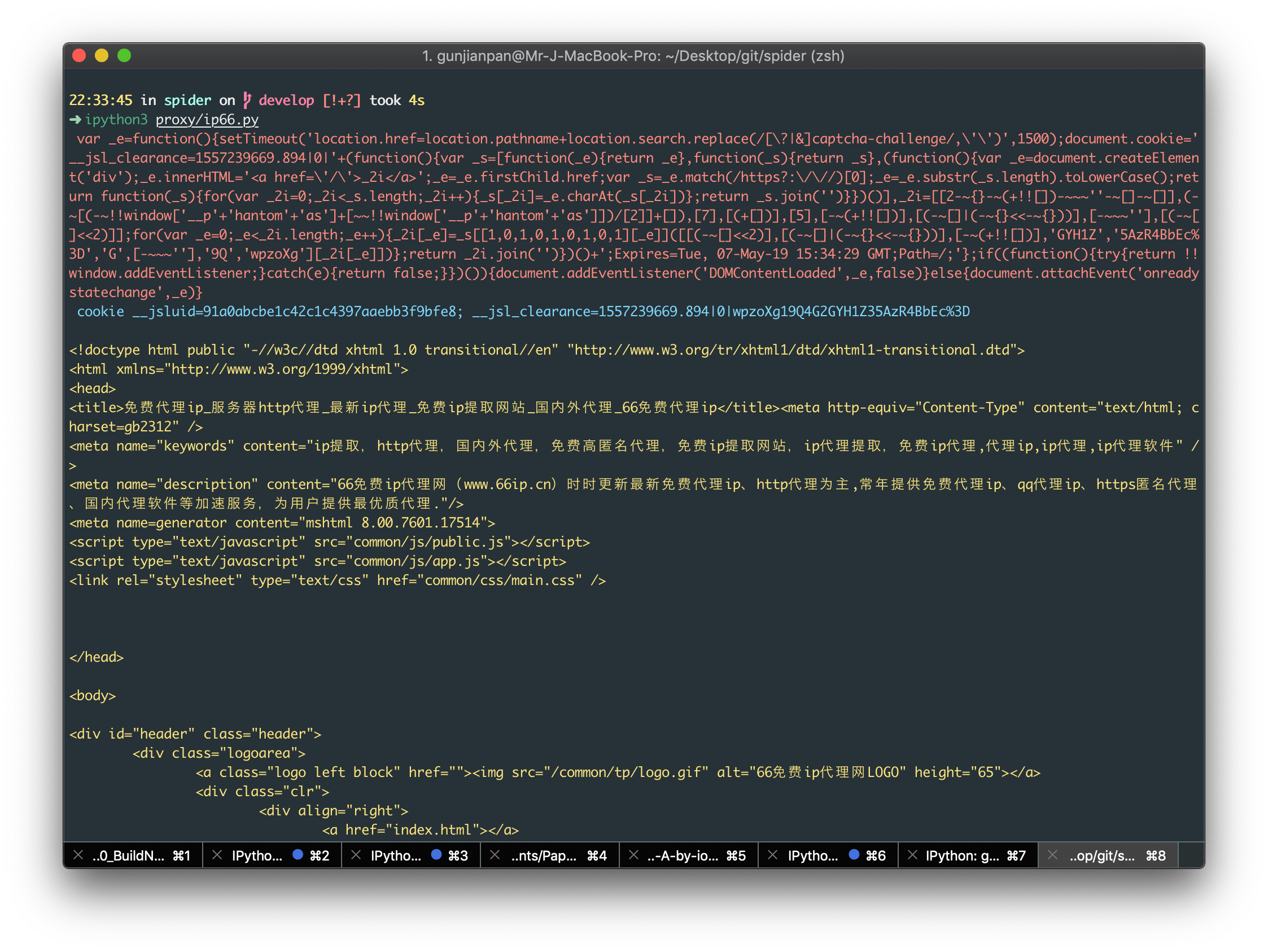
Q: @liu wong 一段 js 代码在浏览器上执行的结果和在 python 上用 execjs 执行的结果不一样,有啥原因呢? http://www.66ip.cn/
A: 一般 eval 差异 主要是有编译环境,DOM,py 与 js 的字符规则,context 等有关 像 66ip 这个网站,主要是从 py 与 js 的字符规则不同 + DOM 入手的,当然它也有可能是无意的(毕竟爬虫工程师用的不只是 py) 首次访问 66ip 这个网站,会返回一个 521 的 response,header 里面塞了一个 HTTP-only 的 cookie,body 里面塞了一个 script
var x = "@...".replace(/@*$/, "").split("@"),
y = "...",
f = function(x, y) {
return num;
},
z = f(
y
.match(/\w/g)
.sort(function(x, y) {
return f(x) - f(y);
})
.pop()
);
while (z++)
try {
eval(
y.replace(/\b\w+\b/g, function(y) {
return x[f(y, z) - 1] || "_" + y;
})
);
break;
} catch (_) {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
可以看到 eval 的是 y 字符串用 x 数组做了一个字符替换之后的结果,所以按道理应该和编译环境没有关系,但把 eval 改成 aa 之后放在 py 和放在 node,chrome 中编译结果却不一样 这是因为在 p 正则\b 会被转义为\x80,这就会导致正则匹配不到,就更不可能替换了,导致我们拿到的 eval_script 实际上是一串乱码 这里用 r'{}'.format(eval_script) 来防止特殊符号被转义 剩下的就是 对拿到的 eval_script 进行 dom 替换操作 总的来说是一个挺不错的 js 逆向入门练手项目, 代码量不大,逻辑清晰 具体代码参见iofu728/spider
-------- 原文从这里开始 --------
因为各种原因,这段时间又写了好多爬虫 (不务正业 划掉 😶),也顺带接着这个机会来总结一下,自己认为的爬虫进阶技巧
ps: 爬虫千万条,克制第一条。我们也要照顾一下反爬工程师的感受,克制开多线程,降低并发数
以下代码已开源,基本支持开箱即用,自带高可用代理 IP 池,呜呜呜(开源一时爽,一直开源一直爽 🤧
开胃菜->字体
这基本上已经成了反爬虫工程师最拿手,最常见的一招了。
像猫眼,东方财富,实习僧,天眼查,起点,etc.
简单一点的每次返回一个随机字体(这个随机指的是字形和字符映射关系随机,字形 set,字符 set 还是不变的)
做的狠一点的就连字库也随机一下(是个狠人,这种解决起来成本就有点高了
反爬的基本原理就是利用字体库中不太常用的一些 高位字符字段(比如说 0xEFFF) ,它是uint16。
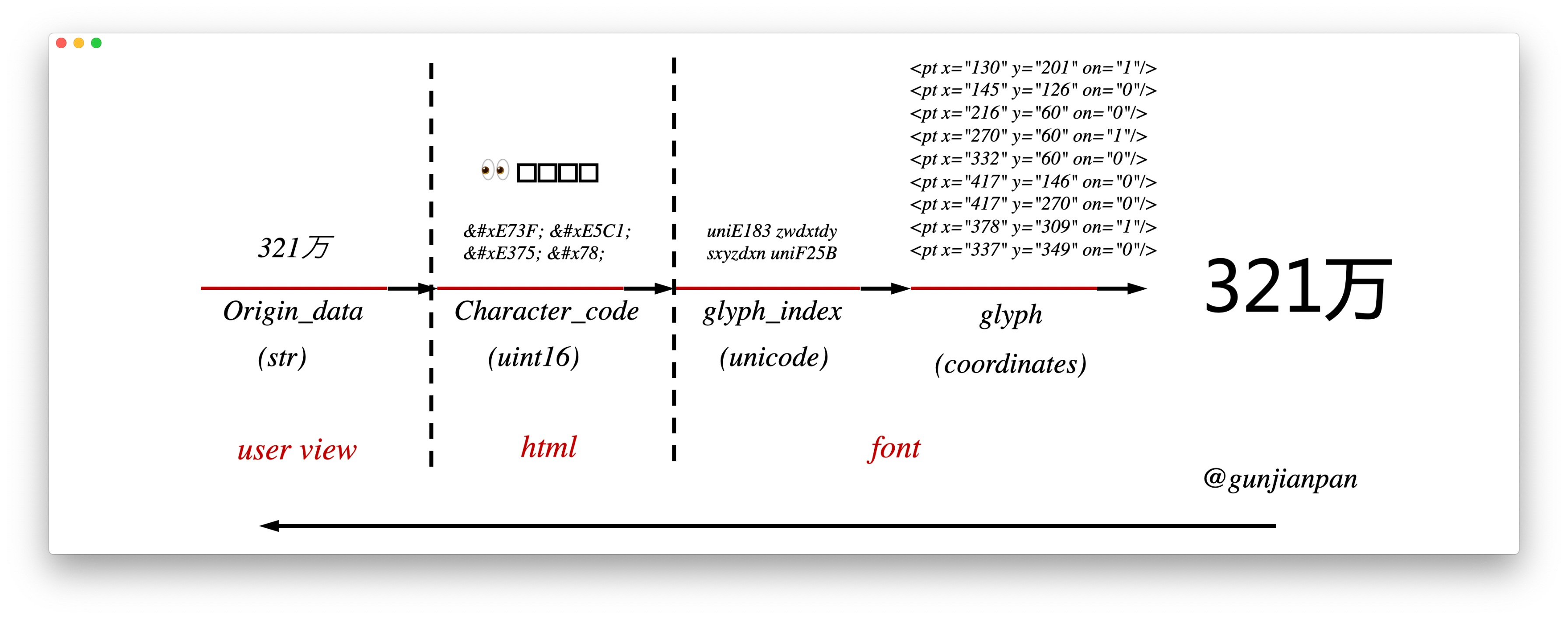
把原始文本替换成这些高位字符,然后使用自定义的一个 font 表示高位字符和字形之间的关系
字形的表示方式,感性的想象一下,大抵就是用类似 svg 之类的坐标点集合的方式来表示
但总是去匹配这很长的一串坐标点来判断是什么字形就显得很低能,就需要有一个能表示字形的索引,于是就有 Glyph index,
然后还有一大堆表和规划, 比如用的最多的camp表, 有兴趣的同学可以参考这篇文章cmap — Character to Glyph Index Mapping Table
字形索引值一般是 Unicode,但要注意不同的字形可能字形索引值一样(相当于发生了 hash 碰撞)
在实操中,利用 fonttools 的包可以解析出来字符编码 uint16 和字形索引 Unicode 之间的映射关系
from fontTools.ttLib import TTFont
font_map = TTFont(font_name).getBestCmap() # uint16 -> unicode
2
一般像这种,操作的字符集不会太大,毕竟太大对自己服务也是一个不小的压力
常见的有数字替换,部分文字替换,像这种反爬模式,利用 selenium,splash,mitm 之类的非网络请求库就没有什么效果了 hhh
因为要考虑到随机 font,即字符 uint16 和字形索引 unicode 之间的关系发生改变,但字形和字形索引 unicode 之间的关系一般不会变。
So, 我们就可以建立一个已知的字形索引 Unicode 与原始字符 str 之间的对应关系 dict_base
当 font 发生改变的时候 字形索引 Unicode 和 uint16 字符之间的关系发生改变,根据 dict_base 反推出字符 uint16 和原始字符 str 之间的关系
举个 🌰, 比如说爬东方财富(个人觉得这是一个特别适合入门的网站,他代码可读性比较强,注释比较多 hhh 很真实 不知道他们前端都是怎么想的)
当然东方财富不是所有页面都采用了 font 欺骗,应该也是出于效率考虑,以http://data.eastmoney.com/bbsj/201806/lrb.html为例
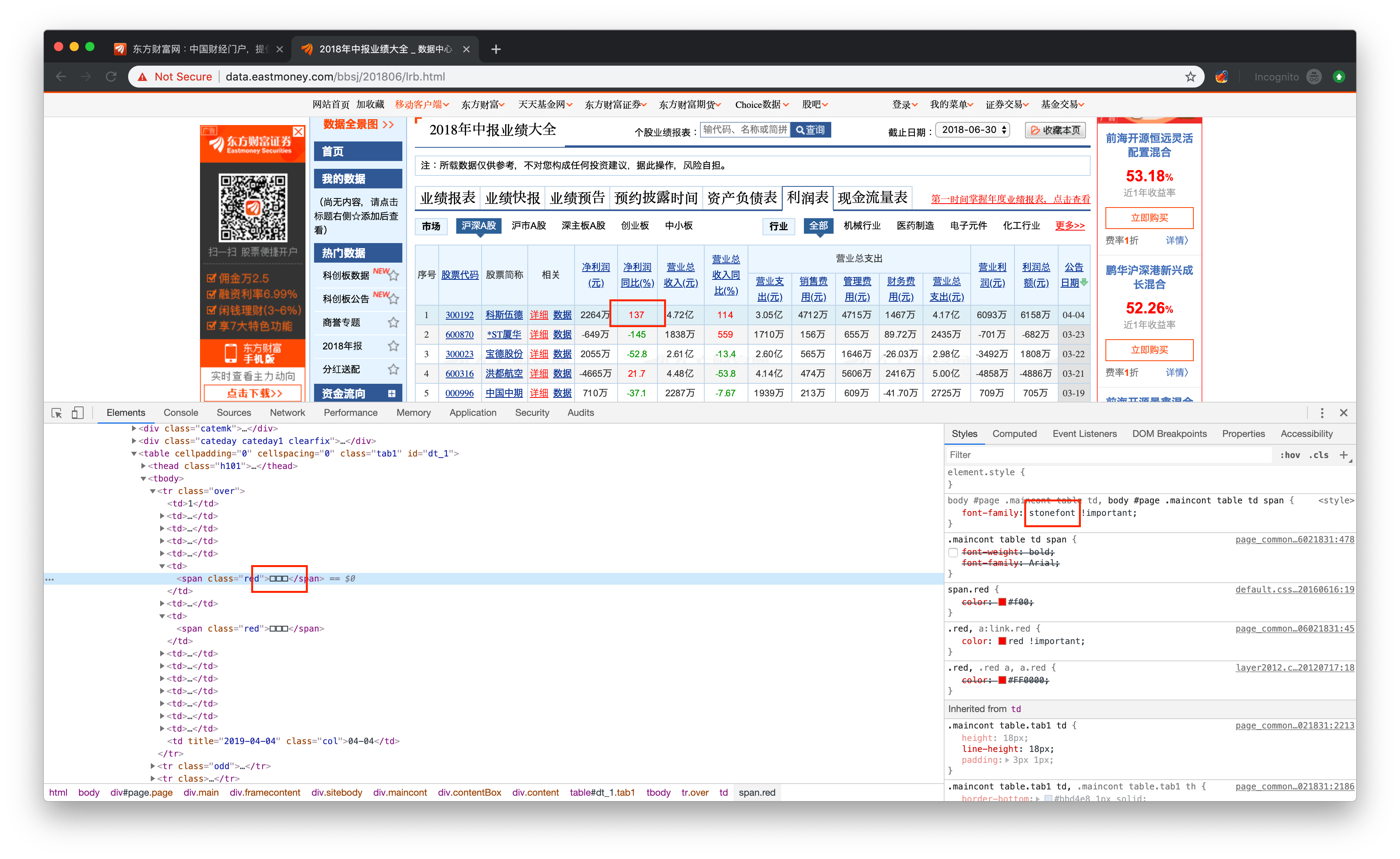
可以看见使用了一个叫做stonefont的 font 来实现字符到字形的映射
经过分析可以发现,table 里面的数据都是预先存放在 html 的 script 里面,直接读 json 的,其格式即已经加密过后的 uint16 字符
既然已经知道了拿到的数据是已经被替换的字符,那么找到 css:stonefont 所引用的字体,把字体 load 都本地分析对比其映射关系即可
因为字体是随机指派的,那么 font_url 就一定不会被写死 css 中 为了使得首次加载时间尽量短也一般不会通过 XHR 来获得,一般都是放在 html 的 script 里面动态 compile 生成
在本例中,font_url 和 data 存放在一起,都在 html 的 script 中。
url = 'http://data.eastmoney.com/bbsj/201806/lrb.html'
req = requests.get(url, headers=header, timeout=30) # need headers
origin_str = req.text
''' parse json '''
begin_index = origin_str.index('defjson')
end_index = origin_str.index(']}},\r\n')
json_str = origin_str[begin_index + 9:end_index + 3]
json_str = json_str.replace('data:', '"data":')
.replace('pages:', '"pages":')
.replace('font:', '"font":')
json_req = json.loads(json_str)
font_url = json_req['font']['WoffUrl']
2
3
4
5
6
7
8
9
10
11
12
13
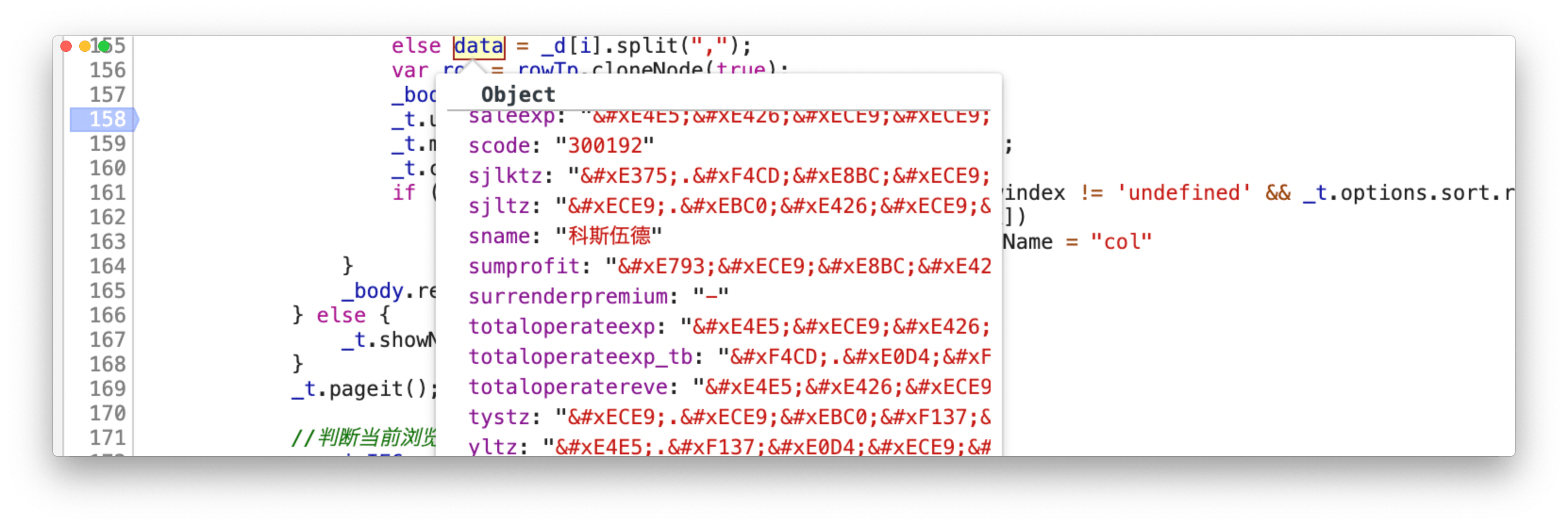
在经过上面脚本解析出来的 json 中,lz 竟然惊奇的发现一个神奇的东西
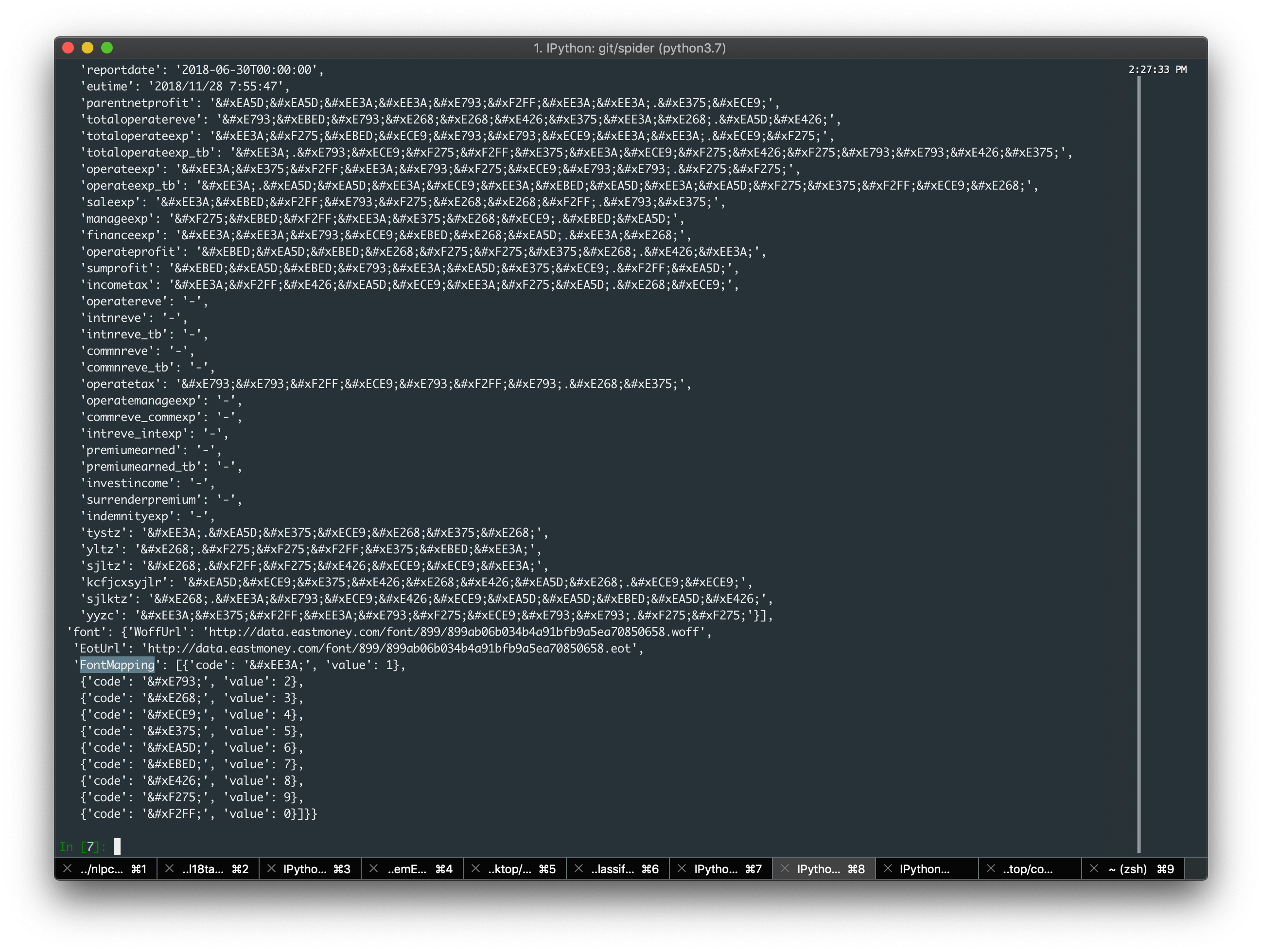
竟然直接把 origin_data 和加密之后的字符 uint16 对应关系直接 po 出来 Excuse me!!! 😯 第一反应 怕不是烟雾弹哦
但是经过对 js 代码的追踪,我可以很负责的告诉你,这就是真的对应关系,至于他们为什么这么奇葩的做,请往下看:
动态把数据塞到http://data.eastmoney.com/js_001/load_table_data_pc.js?201606021831中做的
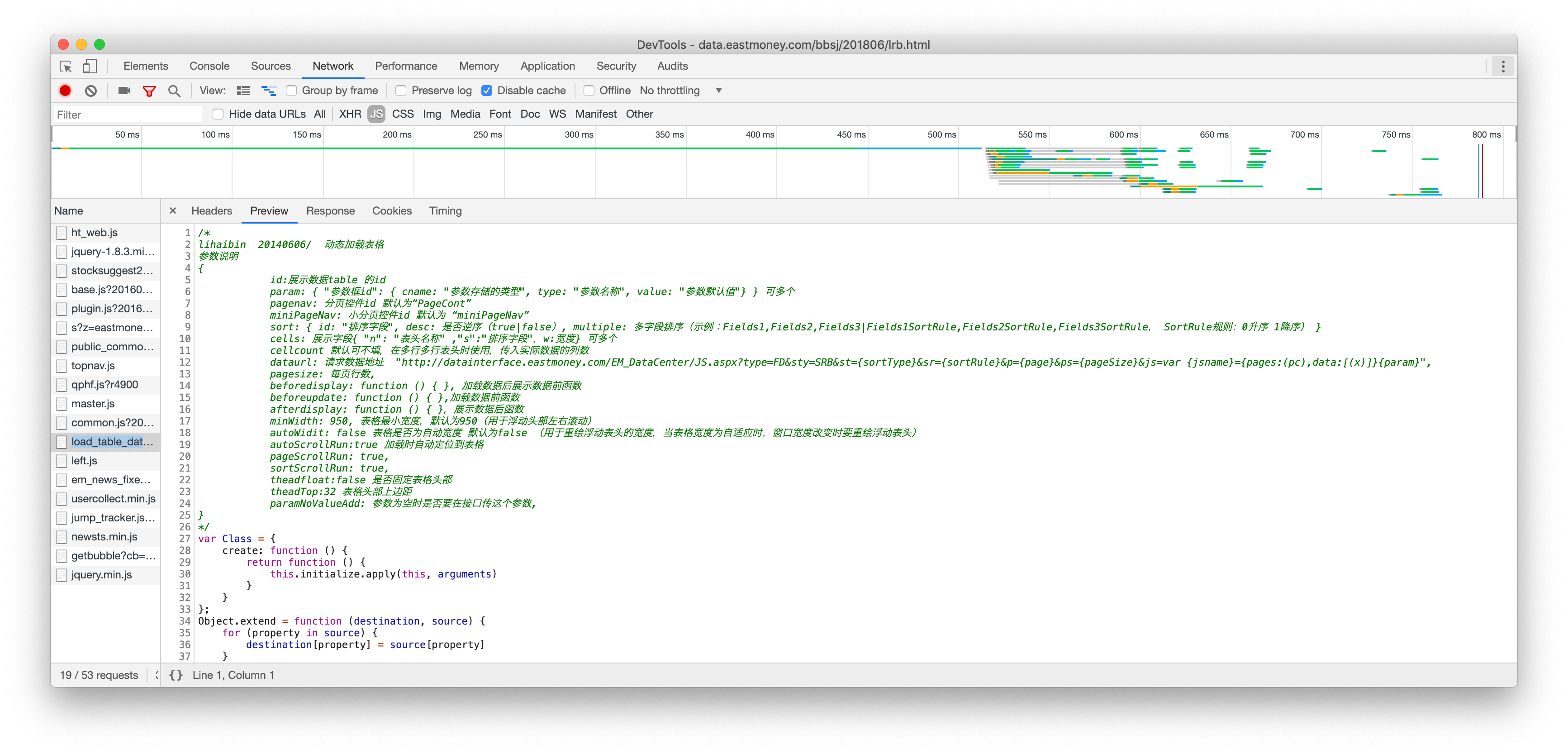
hhh 康康人家的注释,你还好意思写那种稀烂的代码哇(lz 下线了 过于真实 但是生产环境放这种代码 这不就是给大家做教科书的嘛 hhh
display: function () {
var _t = this;
try {
if (_t.options.data.font && _t.options.data.font.WoffUrl) { // 去找font_map
_t.options.font = _t.options.data.font;} else {//设置默认}
_t.loadFontFace(); // update css: stonefont
var _d = _t.options.data.data, _body = _t.options.tbody;
var trs = _body.childNodes;
for (var i = trs.length - 1; i >= 0; i--) {_body.removeChild(trs[i])} // remove tb
if (_d && _d.length && _d[0].stats == undefined) {
for (var i = 0; i < _d.length; i++) {
var data, row = rowTp.cloneNode(true);
_body.appendChild(row);
_t.uncrypt(data) // 解密
_t.maketr(row, data, i, ((_p - 1) * _ps + 1 + i)); // 上颜色
_t.crypt(row) // 加密
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
来看一下把数据填充到 tb 这个过程的入口函数(省去了一些不太重要的逻辑
从json中找font信息 -> 动态修改css:stonefont -> 删除tb子标签 -> 解密数据(uncrypt) -> 给数据加样式(maketr) -> 对加完样式的文本重新加密(crypt) -> 塞回tb标签
一开始,我看到解密再加密这个过程是懵逼的,'难不成加密解密用的不是一个秘钥'。看到后面我发现我错了,两个 font_map 一毛一样呀
分析一下,当时他们加这个应该是前端不太好处理样式问题,弄的一个折中方案(对吗,前端也没办法解析 font 内的映射关系
其实加一个映射关系不变的正负标志位不就好了(毕竟你显示样式主要看数字正负号,要处理显示万,千等位数完全可以根据字符位数来
这样改完全就失去了本来反爬设置的效果,当然这给了广大致力于学习爬虫的同学一个入门的机会 😘
分析到这里,理下思路,通过 json 解析出的 font_map 生成一个 base 映射关系(其实你也可以直接用 font_map 进行解析 hhh
然后每次把 font load 到本地对比 base 映射关系,生成这个字体对应的映射关系
具体代码可见eastmoney.eastmoney
稍微提一下自己踩的两个坑
error: unpack requires a buffer of 20 bytes
requests.text -> str,
requests.content-> byte or str
How to analysis font
- 利用 fonttools 包
- 获得 cmap 表
TTFont().getBestCamp() - 和 base 进行对比
冷菜->js compile
这个话题,其实最近另外一个 dalao 在知乎讲过,我就大概提一下
一开始看到那个面试题http://shaoq.com:7777/exam的时候也是比较惊奇的,以前遇到 css 里面塞信息的还是比较少的, 上一个还是 goubanjia???
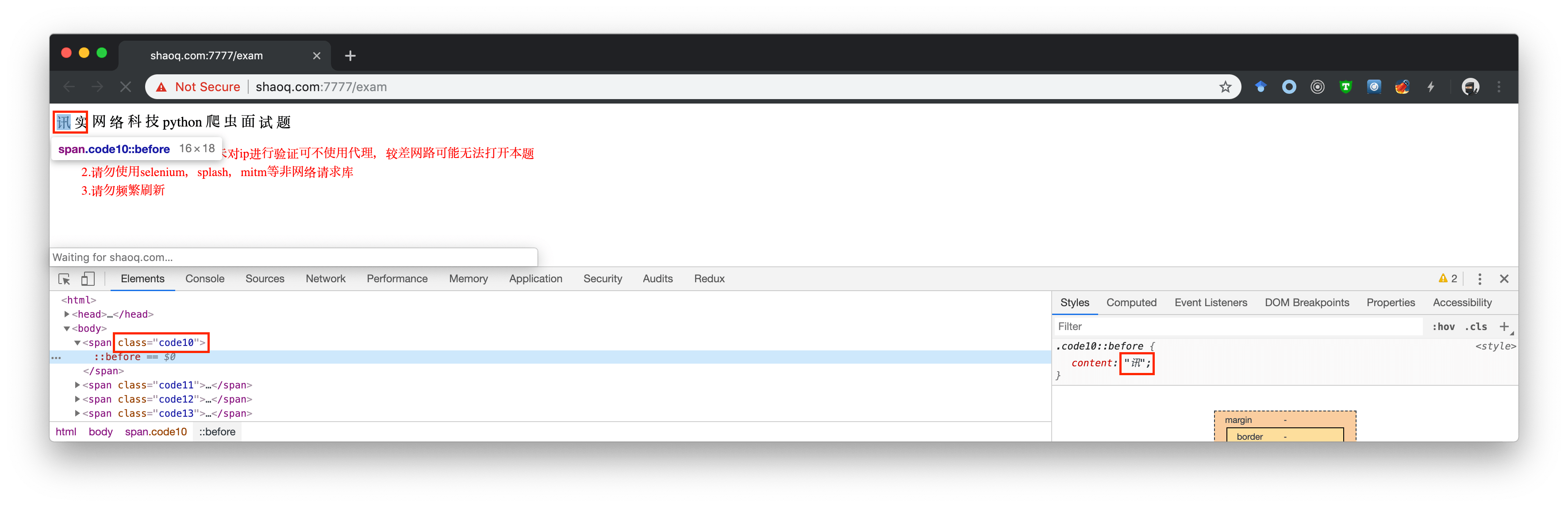
只不过 goubanjia 的 css 是静态资源,这边 shaoq 用的是动态编译生成,其实还是差不多的,用一下 execjs + jsdom 进行动态编译 js,得到 style
shaoq 的思路:
首次请求获得cookie -> 请求image -> 等5.5s(注意一定是获得html后5.5s) -> 编译js 获得css -> 塞css的content到对应的标签(这一步需要把一些无关的标签剔除掉)
具体代码可见exam.shaoq
然后也附一下自己踩得坑
Can't get true html
Wait time must be 5.5s.
So you can use
threadingorawait asyncio.gatheroraiohttpto request image
Error: Cannot find module 'jsdom'
jsdom must install in local not in global
remove subtree & edit subtree & re.findall
subtree.extract()
subtree.string = new_string
parent_tree.find_all(re.compile('''))
2
3
甜点->websocket
其实这一块内容就和压测有点像了,用处不只是用来爬取信息,很多时候是用来模拟长连接请求
如果开多进程的话实际上效果就是压测 websocket(所以大家悠着点
首先,什么是长连接, 什么是 websocket,什么是 socket
socket,实际上是一个 unix 的概念。我们知道进程之间的通信问题称之为 IPC(InterProcess Communication, IPC)有管道,消息队列,信号量,共享存储,套接字 Socket 等方式
但这些都是在本机范围的通信,即 Unix 域内 IPC,如果把问题拓展到网络内的通信则变成了网络域套接字
因为网络通信的不可信,需要做一系列的计算校验和,执行协议处理,添加或删除网络报头,产生相应的顺序号,发送确认报文(注意理解这一部分内容,对后面读懂、模拟二进制报文很有帮助)
http 是一种基于 TCP 的短链接,三次握手 🤝 之后建立连接,完成任务之后,马上四次握手 🤝 关闭连接
长连接则是在完成任务之后不立即关闭连接,而是当连接的一方退出之后才关闭连接,常见的协议有 websocket 和 http 的长连接
我们知道 TCP 是可靠的连接,建立连接的代价比 UDP 大多了,如果有一个需求需要反复建立连接,比如说聊天,直播弹幕数千万用户反复请求短链接,会花费大量时间在协议上
另外也是为了能使得服务器可以主动发生给用户数据,而不是客户端轮询,websocket 就腾空出世
在 java 中建立长连接常用 Netty 解决
在 py 里面就得用一下异步 io 库 asyncio 和 异步 httpaiohttp (hhh 竟然还资瓷 websocket)
建立 websocket 连接的过程并不复杂,关键是分析 header 头部字节含义
举个 🌰,比如说爬取 b 站 up 主视频的实时访问量,以 18 年百大第一的炒面筋为例https://www.bilibili.com/video/av21061574
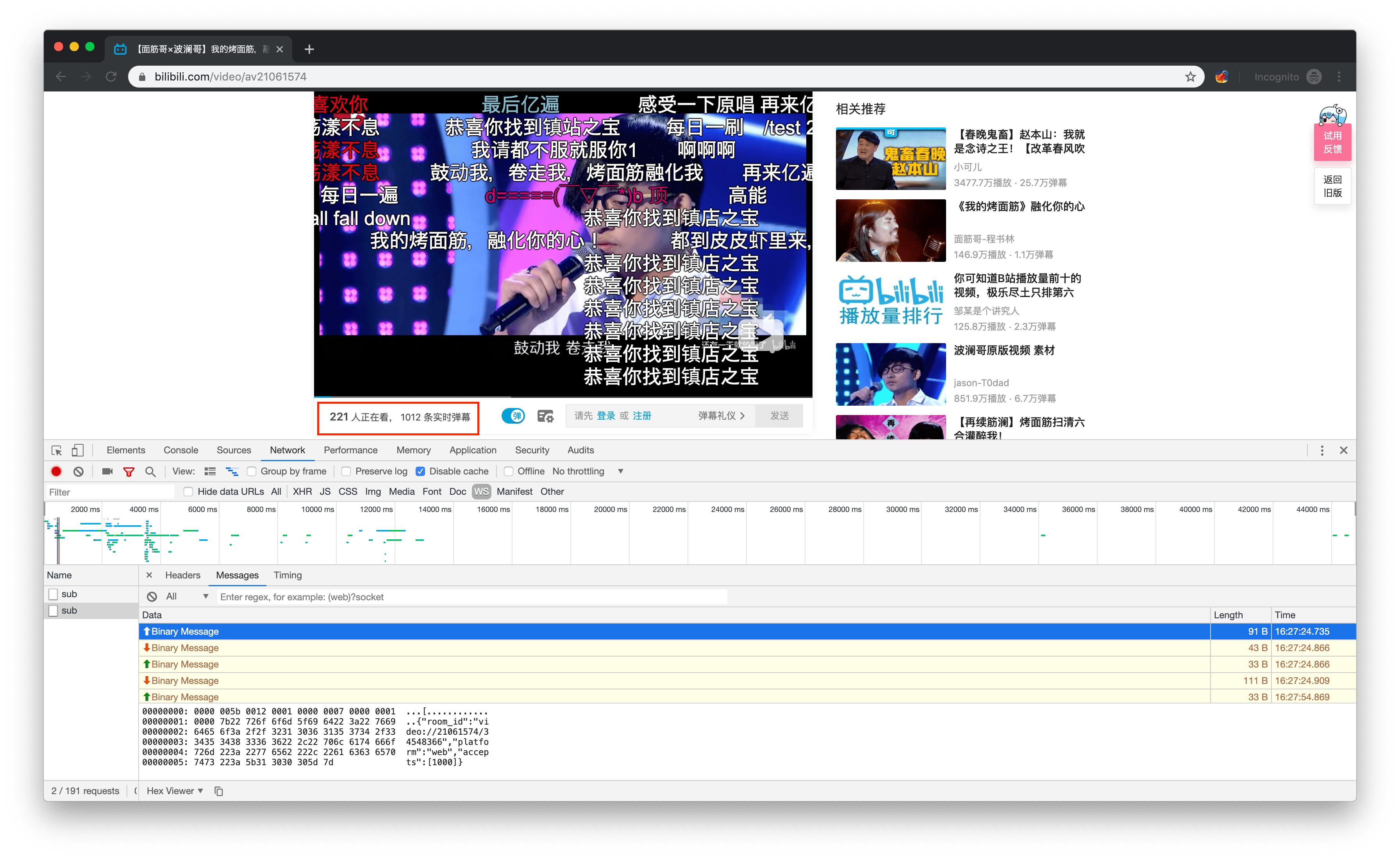
分析 network 可以发现视频左下角的 XX 人正在看,XX 条实时弹幕,新增弹幕推送都是基于 websocket 协议进行传输的
再来仔细研究一下具体发送的字节码
Send
00000000: 0000 005b 0012 0001 0000 0007 0000 0001 ...[............
00000001: 0000 7b22 726f 6f6d 5f69 6422 3a22 7669 ..{"room_id":"vi
00000002: 6465 6f3a 2f2f 3231 3036 3135 3734 2f33 deo://21061574/3
00000003: 3435 3438 3336 3622 2c22 706c 6174 666f 4548366","platfo
00000004: 726d 223a 2277 6562 222c 2261 6363 6570 rm":"web","accep
00000005: 7473 223a 5b31 3030 305d 7d ts":[1000]}
00000000: 0000 0021 0012 0001 0000 0002 0000 0002 ...!............ 30s heart beat
00000001: 0000 5b6f 626a 6563 7420 4f62 6a65 6374 ..[object Object
00000002: 5d ]
00000000: 0000 0021 0012 0001 0000 0002 0000 0003 ...!............
00000001: 0000 5b6f 626a 6563 7420 4f62 6a65 6374 ..[object Object
00000002: 5d ]
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看出字节码用的是大端字节序,前 18 个字节是 header 头,紧跟着的是 body 内容
I | H | H | I | I | H |
|---|---|---|---|---|---|
| 0000 005b | 0012 | 0001 | 0000 0007 | 0000 0001 | 0000 |
| 0000 0021 | 0012 | 0001 | 0000 0002 | 0000 0002 | 0000 |
| 0000 0021 | 0012 | 0001 | 0000 0002 | 0000 0003 | 0000 |
socket 长度 | header 长度 | 协议版本,1 | 操作码 | 序列号 | 0 |
明白这点之后就比较好构造字节码了,先初始化一个 header_struct,然后往 struct 加入每一部分的内容
HEARTBEAT_BODY = '[object Object]'
HEADER_STRUCT = struct.Struct('>I2H2IH')
def parse_struct(self, data: dict, operation: int):
''' parse struct '''
if operation == 7:
body = json.dumps(data).replace(" ", '').encode('utf-8')
else:
body = self.HEARTBEAT_BODY.encode('utf-8')
header = self.HEADER_STRUCT.pack(
self.HEADER_STRUCT.size + len(body),
self.HEADER_STRUCT.size,
1,
operation,
self._count,
0
)
self._count += 1
return header + body
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
需要注意的是建立连接时,所需要 room_id 并不只是 av_id,需要先去 html 中取一下 cid(嗯,只能在 html 中解析,cid 是一个优先级比较高的变量,在基本上后面所有变量中都会使用
def _getroom_id(self, next_to=True, proxy=True):
''' get av room id '''
url = self.ROOM_INIT_URL % self._av_id
html = get_request_proxy(url, 0) if proxy else basic_req(url, 0)
head = html.find_all('head')
if not len(head) or len(head[0].find_all('script')) < 4 or not '{' in head[0].find_all('script')[3].text:
if can_retry(url):
self._getroom_id(proxy=proxy)
else:
self._getroom_id(proxy=False)
next_to = False
if next_to:
script_list = head[0].find_all('script')[3].text
script_begin = script_list.index('{')
script_end = script_list.index(';')
script_data = script_list[script_begin:script_end]
json_data = json.loads(script_data)
if self._p == -1 or len(json_data['videoData']['pages']) < self._p:
self._room_id = json_data['videoData']['cid']
else:
self._room_id = json_data['videoData']['pages'][self._p - 1]['cid']
print('Room_id:', self._room_id)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
注意有些视频可能会有多个 page,每个 page 的 cid 其实是不一样的
Receive
00000000: 0000 002b 0012 0001 0000 0008 0000 0001 ...+............
00000001: 0000 7b22 636f 6465 223a 302c 226d 6573 ..{"code":0,"mes
00000002: 7361 6765 223a 226f 6b22 7d sage":"ok"}
00000000: 0000 006f 0012 0001 0000 0003 0000 0002 ...o............ every 30s
00000001: 0000 7b22 636f 6465 223a 302c 226d 6573 ..{"code":0,"mes
00000002: 7361 6765 223a 2230 222c 2264 6174 6122 sage":"0","data"
00000003: 3a7b 2272 6f6f 6d22 3a7b 226f 6e6c 696e :{"room":{"onlin
00000004: 6522 3a32 3232 2c22 726f 6f6d 5f69 6422 e":222,"room_id"
00000005: 3a22 7669 6465 6f3a 2f2f 3231 3036 3135 :"video://210615
00000006: 3734 2f33 3435 3438 3336 3622 7d7d 7d 74/34548366"}}}
00000000: 0000 007b 0012 0001 0000 0005 0000 0000 ...{............ danmuku 1
00000001: 0000 7b22 636d 6422 3a22 444d 222c 2269 ..{"cmd":"DM","i
00000002: 6e66 6f22 3a5b 2237 312e 3137 2c31 2c32 nfo":["71.17,1,2
00000003: 352c 3136 3737 3732 3135 2c31 3535 3435 5,16777215,15545
00000004: 3339 3238 322c 3136 3739 3335 3332 332c 39282,167935323,
00000005: 302c 6562 3636 3033 6161 2c31 3433 3633 0,eb6603aa,14363
00000006: 3937 3436 3136 3231 3936 3530 222c 22e8 974616219650",".
00000007: 9e8d e58c 96e4 bda0 225d 7d ........"]}
00000000: 0000 0079 0012 0001 0000 0009 0000 0000 ...y............ danmuku2
00000001: 0000 0000 0067 0012 0001 0000 03e8 0000 .....g..........
00000002: 0000 0000 5b22 3731 2e31 372c 312c 3235 ....["71.17,1,25
00000003: 2c31 3637 3737 3231 352c 3135 3534 3533 ,16777215,155453
00000004: 3932 3832 2c31 3637 3933 3533 3233 2c30 9282,167935323,0
00000005: 2c65 6236 3630 3361 612c 3134 3336 3339 ,eb6603aa,143639
00000006: 3734 3631 3632 3139 3635 3022 2c22 e89e 74616219650","..
00000007: 8de5 8c96 e4bd a022 5d ......."]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
可以看出 header 结构和 send 一毛一样,除了收到 danmuku 的时候序列号为 0(这一点也很好理解,因为不是主动客户端发送得到的返回,而是服务端主动推送给客户端的)
- 可以看到当
operation=3的时候,收到了实时在线人数 - 当
operation=5时收到一个 body 里面带一个 json 的 commond,其中的cmd内容表示具体的类别 - 当
operation=9的时候,实际上是两个嵌套字节码,里面那个operation=0x03e8=1000, 里面存放的是一个 list
总结一下 operation
| 操作码 | 含义 |
|---|---|
| 2 | 发送心跳包 |
| 3 | 在线数据 |
| 5 | cmd 模式 具体看['cmd'] |
| 7 | 建立连接 |
| 8 | 连接建立成功 |
| 9 | 嵌套header |
| 1000 | danmuka list |
看下效果
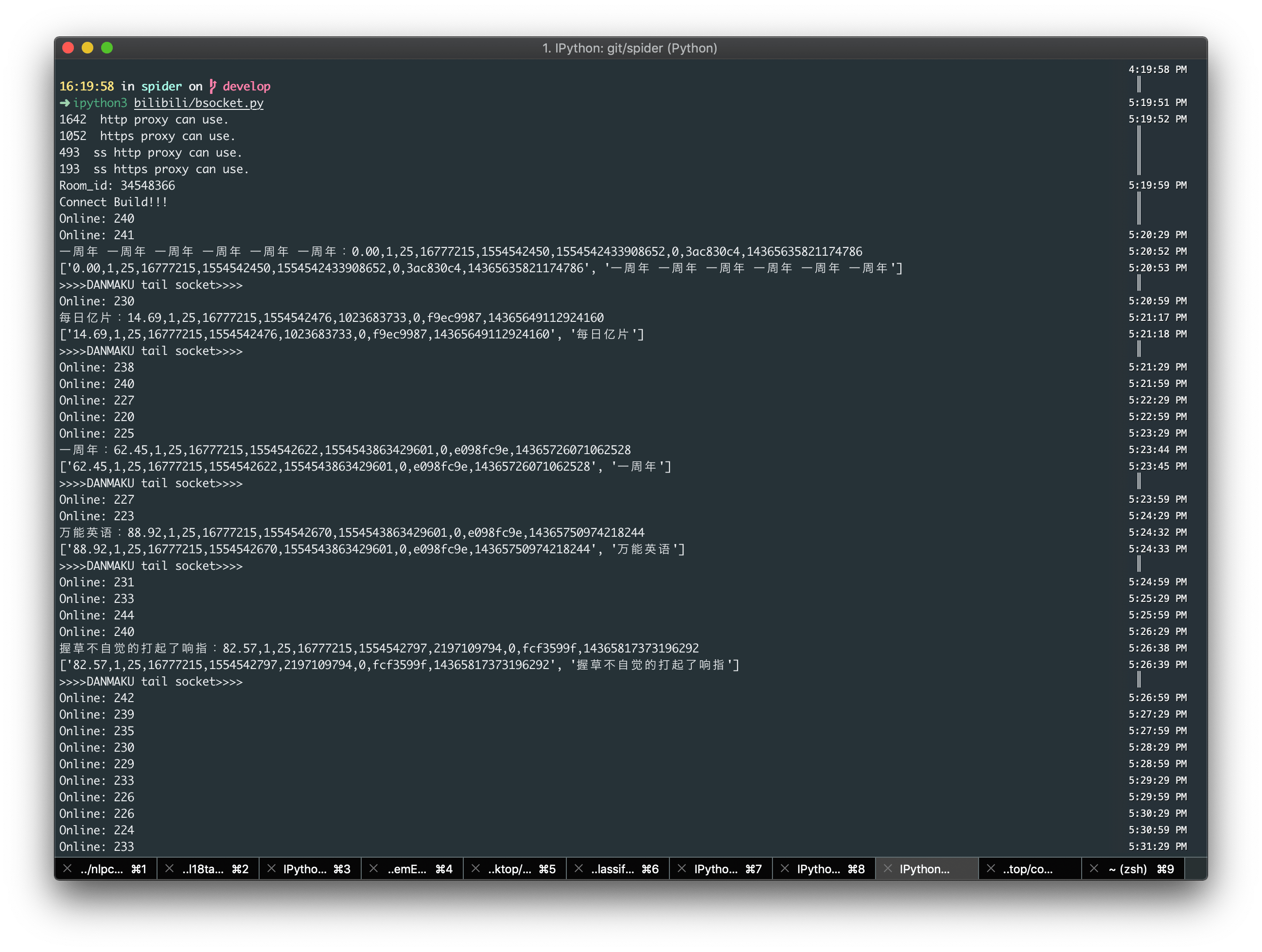
具体代码可见bilibili/bsocket.py
另外开发了一套根据排行榜爬取 up 时序累计数据,附带监控评论内容的系统,可用于分析 b 站视频评分原理的分析,支持开箱即用,欢迎 star
如果有做 b 站直播数据的爬取可以参考另外一位 dalao 的博客,直播的字节码规则略有不同
好了,大概的爬虫进阶技巧就说到这,欢迎各位 dalao 批评指正,转载请联系博主