从高可用IP代理池到千万级网易云音乐数据爬取的实现
首先 ㊗ ️ 大家 1024 快乐
之前写了第一版网易云爬虫
逻辑比较简单
总结一下,就是:
- 抓取各分类下歌单 id
- 根据歌单 id, 获得这个歌单 id 下的歌曲详情
- 把拿到的数据存到落到本地文件,最后利用shell 脚本进行数据统计
- 为了提高效率采用多线程
- 这版线程数开的有点多,建议在docker环境中启,否则你的电脑就不属于你了
整体架构图
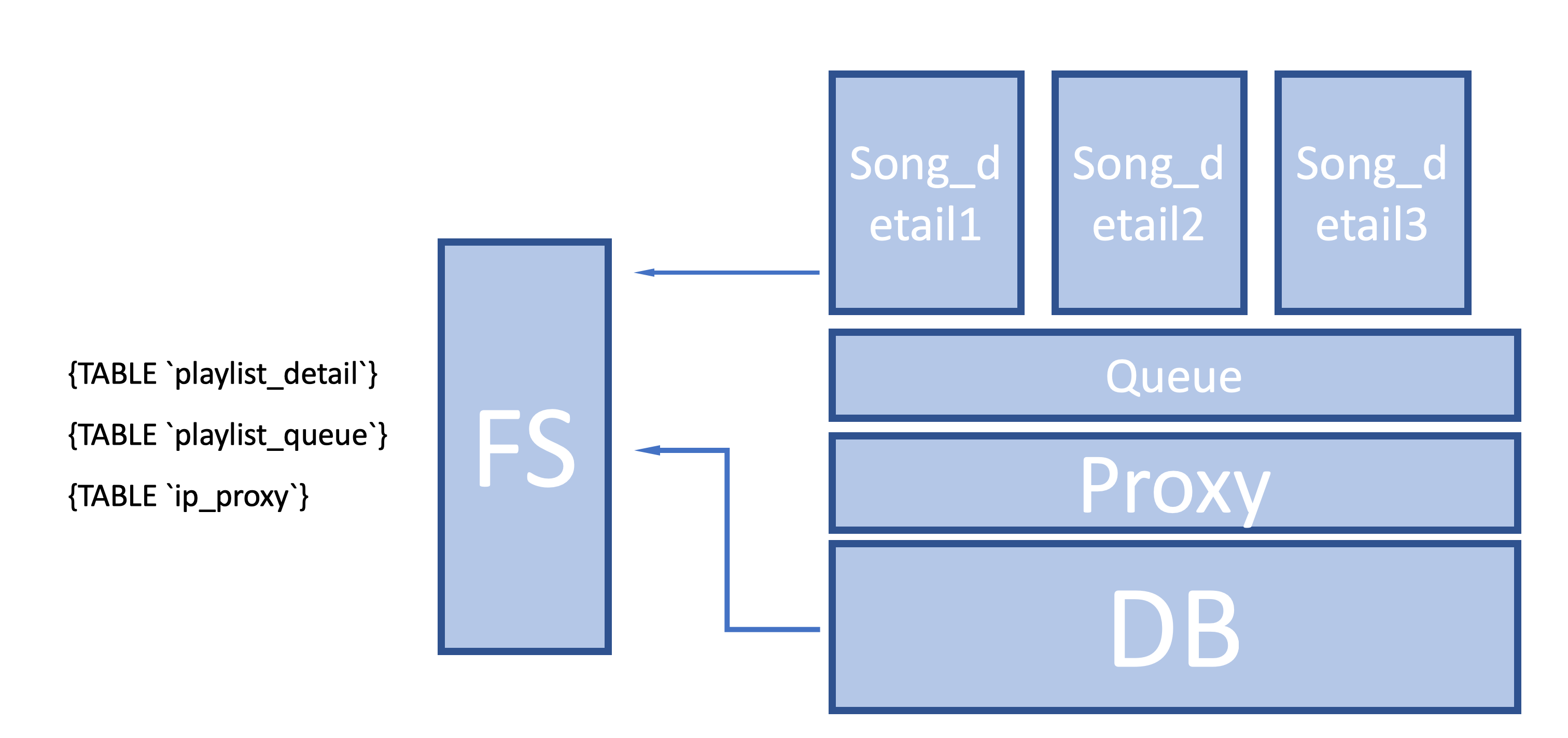
Trouble
第一版 爬虫 看起来没什么毛病
但 还是会有一些问题
- 你可能会有疑问 这么大的一个公司 怎么没有反爬策略
- 怎么可以让我这么肆无忌惮的爬
- 这可是线上服务 一个个请求都是压力
- 落磁盘落在文件里,虽然处理数据也很方便,但数据的关系不够明显
- 这个看起来很简单 就是落数据库
Netease Anti-Spider
第一个问题 其实 你在分析数据的时候就会发现一些端疑
为啥一个那么火的歌单只有一首歌?蛤
实际上这是网易云音乐的一个防爬机制
在短时间请求比较大的时候会触发
在我尝试过程中 基本上在请求 8k-1w 次的时候会发现
按每次请求 200ms 计算,开 18 个线程 一秒请求 100 次
QPS 就达到 6k
如果我多开几个爬虫 那么就会网易云的监控就会很可怕
要知道 PDD 一般服务的 QPS 也就几十万
所以 为了防我们这种新手
网易云造了一些200的 Response,基本数据也是一致的
只是数据量 会少一点
比如说一个歌单只返回一首歌的信息(划重点 这是我们接下来 验证 IP 是否可用的一个有效判据)
问题找到了,那么改如何解决:
一种办法 就是 换物理 IP
用人话说 就是 你在大兴 爬爬 然后 跑到本部去爬
嗯 LZ 在最开始也干过这种事情
导致很多物理 IP 现在可能也不能用 hhh
当然根本的解决策略就是建立代理 IP 池
Proxy 代理池
- 首先 什么是代理?
代理就是 有一个服务器代替你做 你想做的事情
代理 IP 做的事情 就是 把你原本自己发出去的请求 借助代理服务器的 ✋ 发出去
保密做的好的 就叫高匿
一般用的 ShadowSockets 就是一种 Socket5 代理
我们这里要用的则是 Http,Https 代理
尤其更需要 Http 的代理
Xici
xici 代理 是我爬的第一个 Free Proxy 网站
当时爬了 20 页只找到 7 个能用的
然后随机选取一个作为代理
想的挺好的 这次应该不会被封了吧
结果 快到 3w 歌单的时候 pia 机 没了
所以 痛定思痛 觉得建立一个 Proxy 代理池 而且要是高可用的
以上就是 V1.5 版
虽然没有多少代理 IP 但借助着精湛的 转移技术 还是爬取了总计 10.2w 歌单 12780274 首,去重后 1099542
怕大家数不清楚 以上 = 1.2kw/ 110w
但拿到数据只是第一步 基于这些数据可以做很多事情
我们看 得到的数据大概4M*73 = 296M
如果数据量达到 GB 级别 shell 就不太适用 就可以用MapReduce 进行处理,此处参考写的另外一篇 blog
Goubanjia
在爬代理网站 建立代理池的过程中,发现一些很好玩的事情
比如说这个代理网站 Goubanjia
做最基本的 html 解析,可以得到下面的内容
In [9]: html = a.get_html('http://www.goubanjia.com', {}, 'www.goubanjia.com')
In [10]: trs = html.find_all('tr', class_=['warning', 'success'])
In [11]: tds = trs[0].find_all('td')
In [12]: tds[0].find_all(['div', 'span', 'p'])
Out[12]:
[<p style="display: none;">4</p>,
<span>4</span>,
<div style="display:inline-block;">7.</div>,
<span style="display: inline-block;"></span>,
<div style="display:inline-block;">9</div>,
<p style="display: none;">3</p>,
<span>3</span>,
<div style="display: inline-block;"></div>,
<p style="display: none;">.2</p>,
<span>.2</span>,
<span style="display:inline-block;">5</span>,
<p style="display: none;">1.</p>,
<span>1.</span>,
<span style="display:inline-block;">9</span>,
<p style="display:none;"></p>,
<span></span>,
<div style="display: inline-block;">4</div>,
<span class="port GEA">8174</span>]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
好像没什么异常 就是把 Ip 分开来了 拼接一下不就行了
447.933.251.1.94:8174
好像 这不太像一个 IP 地址
实际上懂一点 Html 知识的可能会发现*style="display:none;"*
这个一个隐藏的 style 实际上是不显示的意思
发现这点之后 好像就很简单了
tds[0].find_all(['div', 'span', not 'p'], class_=not 'port')
但 这只是这个网站两年前做的版本 好戏还在后头
我把得到的 ip 进行测试 然后一惊
woc 费那么大劲 一个都不能用 一个都不能用 干嘛还这么用力来防
总觉得有、不太对
然后突然发现 拿到的Port 和网站上看到的 好像不太一样
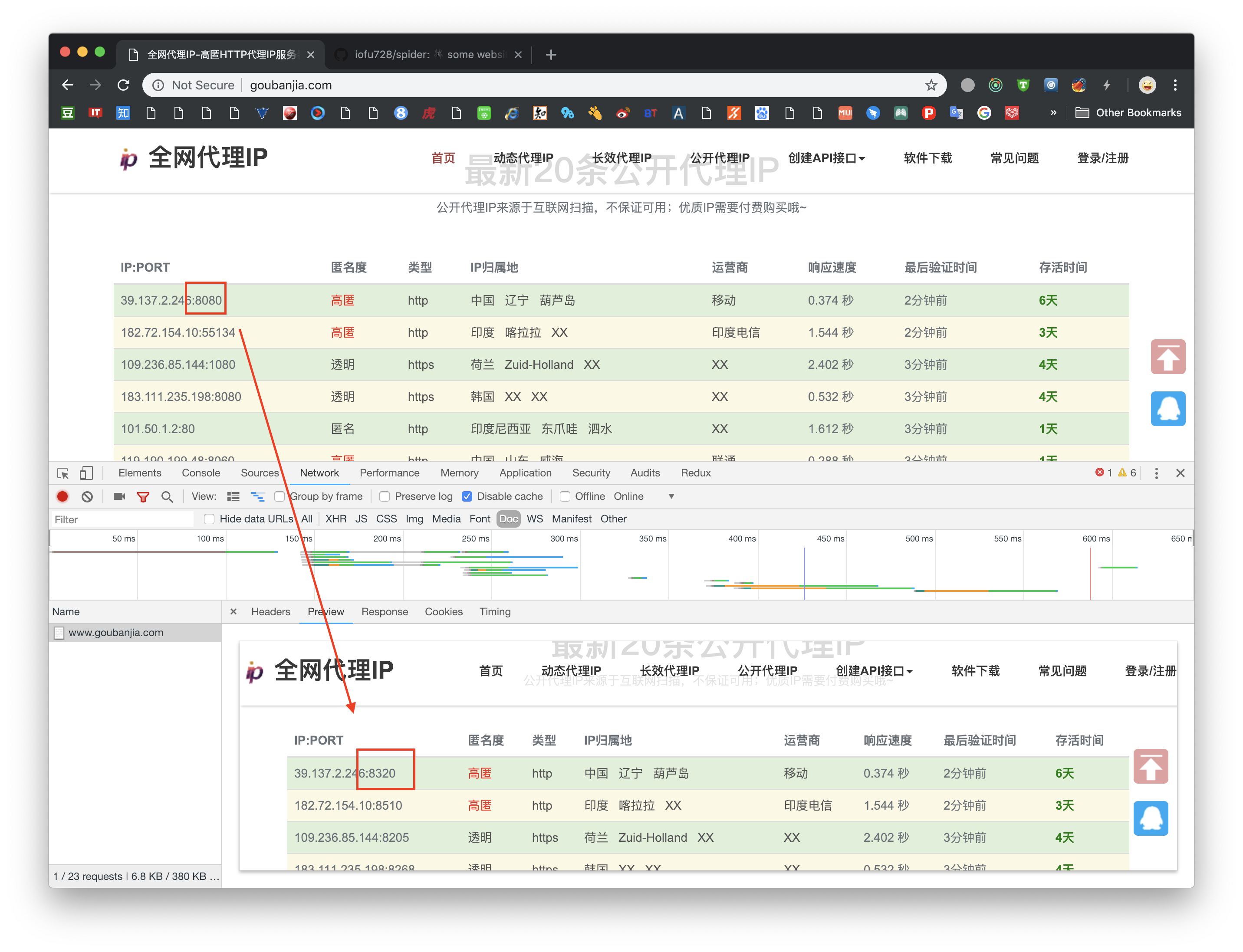
这个时候想到 上课讲的 wolf 字体欺骗
检查字体发现再正常不过了
再回头来看这个代码*<span class="port GEA">8174</span>*
一开始怀疑对象 也是 CSS 这个 class 会不会有什么特殊的地方
想了半天 也排查了所以 css js
发现如果把*http://www.goubanjia.com/theme/goubanjia/javascript/pde.js?v=1.0*禁掉 就会显示 Html 的内容
有同学说看 js 代码 实际上 看不出来什么东西
再看引了 JQuery 的包 猜想应该是 JQuery 动态修改 Html
但知道 这个并没有用 并不能帮助我们解密
这就是一个 encode decode 的过程
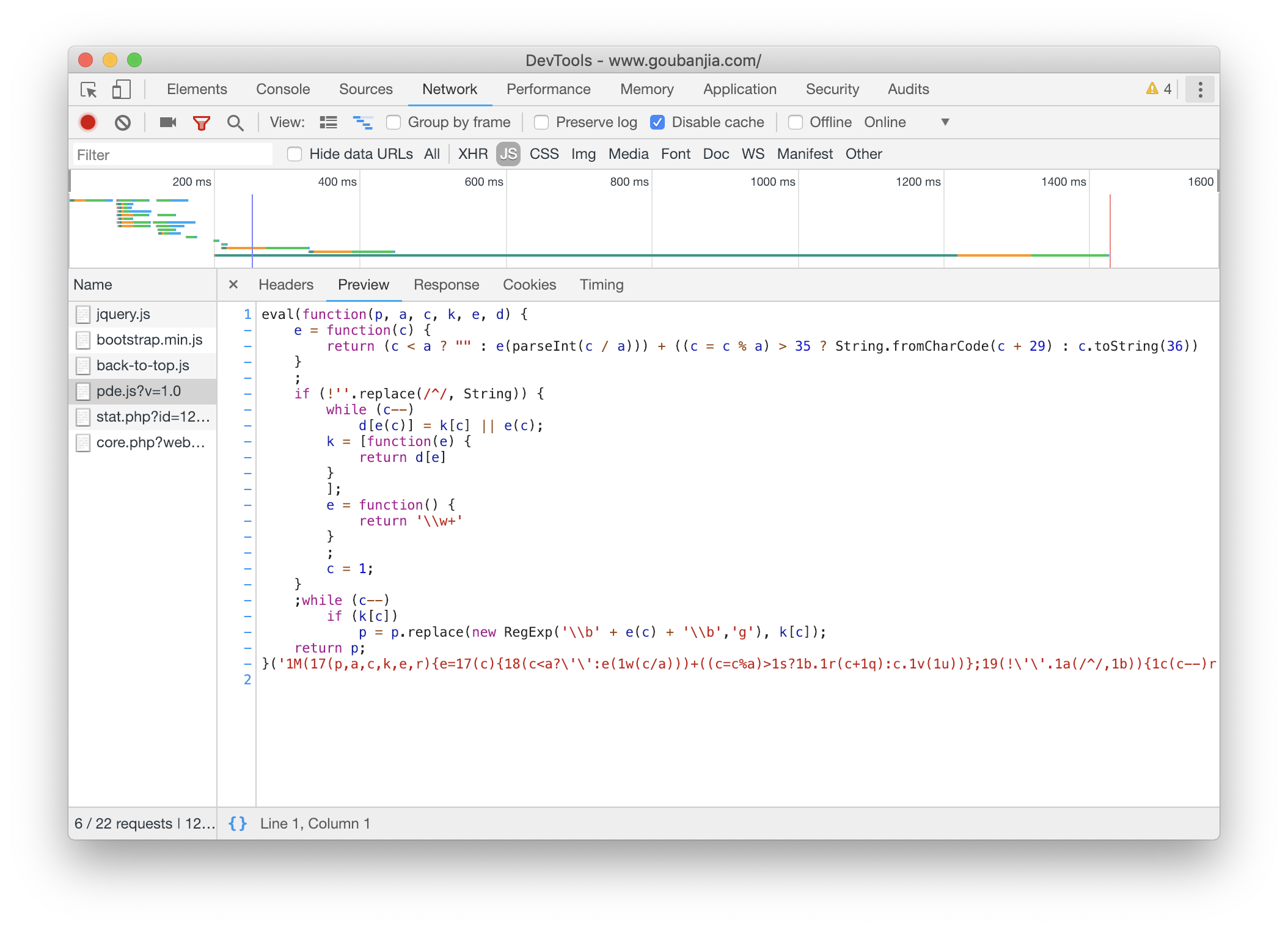
好像 port 后面的字母和端口号有一一映射关系
那么 我们 进入到最原始的方式:通过枚举 找规律

然后我们就会 变得很机智 发现这个密码就是把字母转化成数字 然后/8
嗯 这应该是 第一个解密 goubanjie 骚操作的 blog
然后 我们发现这个网站更新很频繁 但一次只能拿到 20 条
于是 写个定时任务 就是一个很合理的需求
gatherproxy
其实国内代理 都太势利了 能用的本来就不多 还收费
国外的代理 就很慷慨
比如说gatherproxy 这也是我们的主力代理 Ip
和别的不一样 这个网站吧所有 ip 都开放给你下载 不提倡写爬虫
那么问题就变为 如何在较短时间内把 1w+ 对应的 http/https 代理是否可用检验出来 然后写到 DB 中
想要快 只能 开多线程
但写库不能在多线程中
我们知道 Innodb 因为资瓷事务 有严格的写锁机制
短时间 竞争写操作 会造成 写失败操作
于是第一套方案 就是等所有 判断结束之后 再写
测试发现 写效率 挺高的 1s 内完成 1k 条 Insert 语句
但实际上频繁的写操作不太友好
所以改成聚类 通过一次 sql 操作 完成 1k 条数据的插入
这样就解决了慢 SQL 的问题
TestDb()
当然 代理具有极强的时效性
如何在短时间内判断数据库中大量的代理数据是否可用(目前为止已经有 2.2w 代理 ip 数据) 也是一个问题
解决方案 同样是 多线程
但同时为了保证代理 Ip 的质量 采用 3 次验证机制
通过 is_failured 字段 进行判断 每失效一次+1 直到 is_failured 到 5 则不在检测
如果可用一次 is_failured 置为 0
不可靠
实际上就算之前的三层检验 拿到的可用的代理
在实际运用当中 还是会出现请求失败的现象
所以 对于真实爬取场景 为保证每一个数据的都能被爬取到
对每个任务增加 Retry 机制 并记录爬取进度 To DB
然后 其实 Proxy 特别依赖network
比如说 有一次连上了 隔壁寝室的 WiFi别问我怎么连上的 密码真的简单
然后经过 testdb 之后可用的 Ip 数就掉零
然后 实验证明 Https 的代理 比较不稳定 十分需要 retry 机制
对于本次爬虫而言 实际上 Https 的接口没有加 反爬机制 不用代理也行
DB
DB 采用 MySQL
一个是 因为熟悉
另外一个可用方便显示数据的关系
但实际上大数据下 MySQL 的性能优化 有很多功课可以做
慢 SQL
前面说的 读写IP 池 是一种慢 SQL
实际上 写 playlist_queue表也是
我们一次拿到 1k+个歌单 Id 需要在短时间 进行判断写入/更新进 DB
我们可以用 Replace Into 代替 Update 进行更新
所有操作做聚类 一条 SQL 代替数 k 条 SQL
但在playlist_detail这张表中
首先 单条数据 Size 大
其次 需要一次插入七八万条数据 这已经是聚类过的 单classify进行统计处理
这 Insert 也不管用
测试中 6w 数据
分成 5k 一组 一条也写不进去 3k 一组 能写三条 1k 一组 能写 10 条 500 一组 中间休息 0.2s 能写 20 组
仔细看一下 发现block 大小 和 能写入的量 直接 并没有直接关系
该写不进去的 照样写不进去
最后 采用先写到本地文件中
再通过 Load data 导入 MySQL
那 我们 为啥 还要写库 二进制文件不是挺好的吗 shell 脚本多少好用
Finish
于是第二版 主要解决了以上技术难题
剩下还有一些零零散散的小问题 主要是多线程 一些写、更新比较繁琐的地方
总的来说 实现
- 高可用代理 IP 库建立
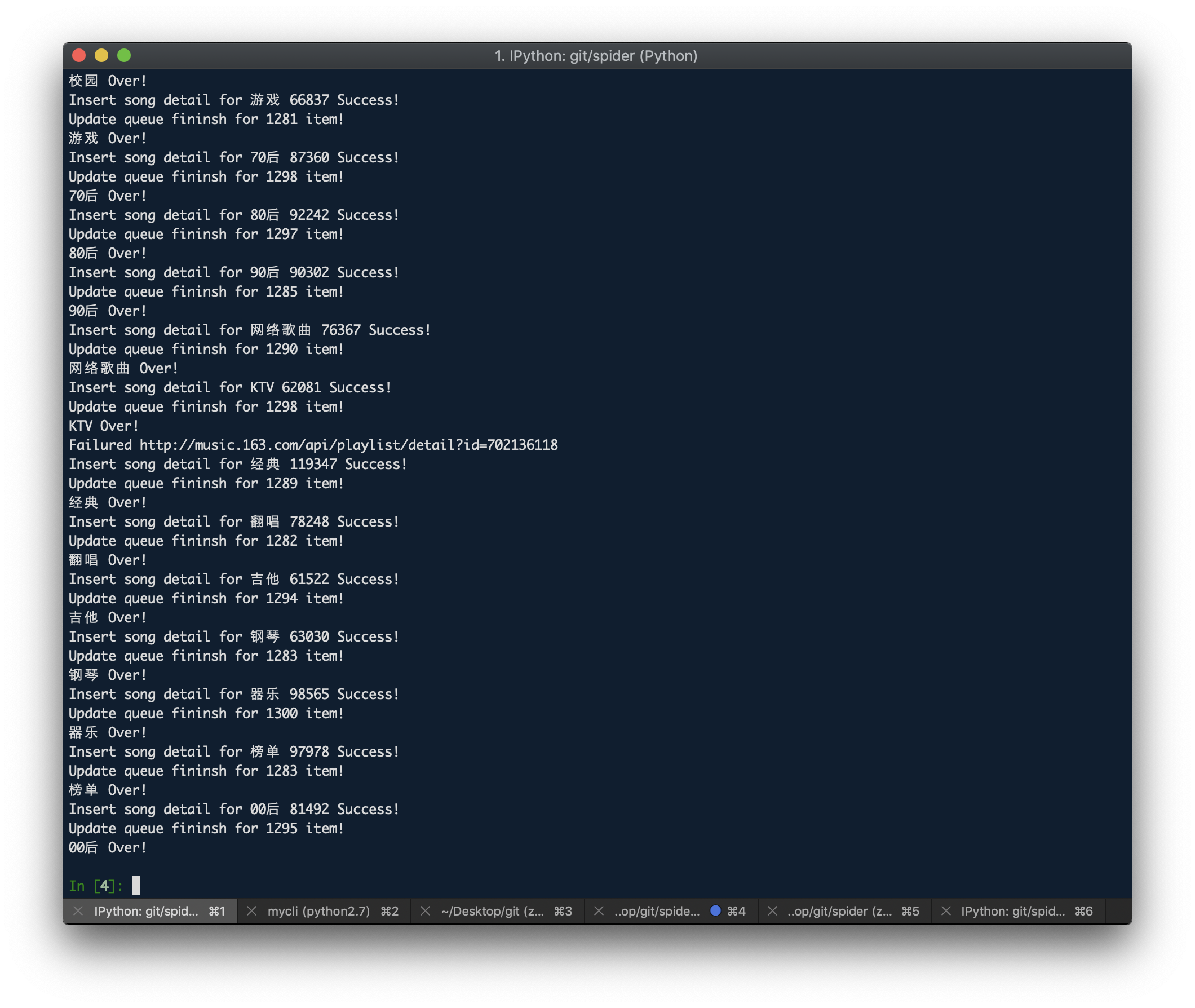
- 资瓷记录爬虫进度的自动化网易云音乐歌单数据爬虫
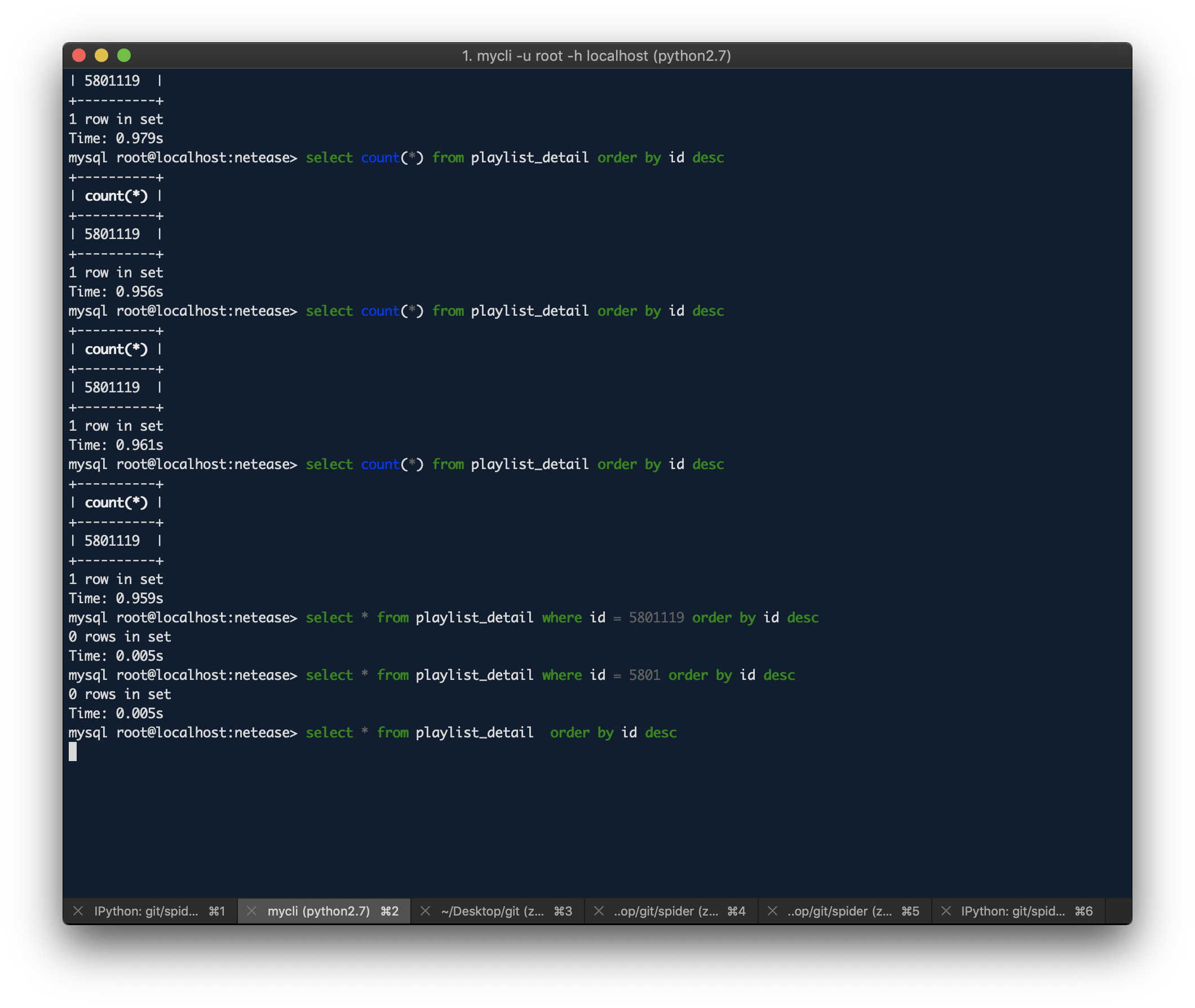
- 完成 6 百 w(5801119)数据爬取,写库操作
Next
- 通过Kafka消费消息队列 来解决 写库量大的问题
- 数据分析 挖频繁模式
- 只爬了 playlist 的数据 其实网易云还有很多可以做的 比如说用户画像 评论之类很有意思的方向
Result
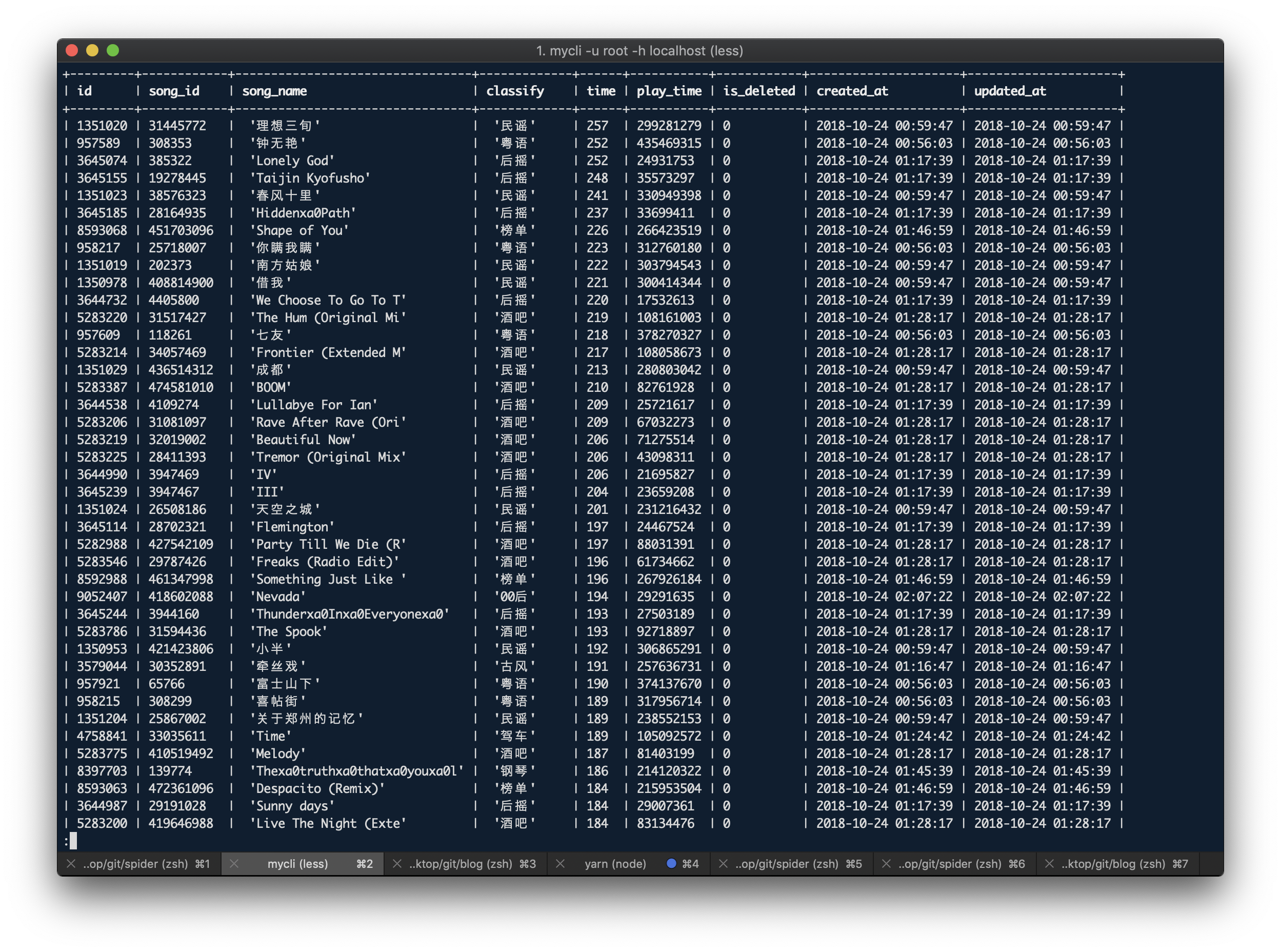
附上出现频次排名前 55 的歌曲
至于为什么是前 55 e
-- 数据采样于 2018.10.23 --
前 1k 名单见GitHub
time song_name
----|-----
6784 Something Just Like This
5814 Shape of You
5720 Time
5585 Alone
5151 Intro
4916 Hello
4833 You
4787 Closer
4312 Nevada
4217 Stay
4142 Faded
4089 说散就散
4070 Animals
3894 往后余生
3650 Home
3645 Without You
3535 Counting Stars
3515 That Girl
3410 HandClap
3300 Higher
3265 Despacito (Remix)
3229 Unity
3198 Havana
3181 起风了(Cover 高橋優)
3148 Forever
3141 Victory
3108 Please Don't Go
3101 Sugar
3080 Beautiful Now
3077 See You Again
3022 Fade
2969 Summer
2940 Seve
2938 The truth that you leave
2861 Life
2853 可能否
2825 We Don't Talk Anymore
2799 Superstar
2795 #Lov3 #Ngẫu Hứng
2793 Try
2759 アイロニ
2730 Hope
2714 Hero
2705 追光者
2679 遇见
2678 いつも何度でも
2654 Let Me Love You
2646 There For You
2643 Trip
2634 BOOM
2626 Fire
2606 Wolves
2600 Friendships (Original Mix)
2597 Freaks (Radio Edit)
2577 全部都是你
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57