DeeCamp 2019 A 记事
DeeCamp Exam A 2019-04-27
- Radio: 5
- blank: 5
- QA: 1
- Time: 90min
总的来说,感觉比去年简单多了(害啪 🚓
update 一下 评论 已经有 dalao 给出第八题 思路 感谢 @熊怡 dalao
思路一:
转换为 d 维空间 n 刀切最多能分为多少块?
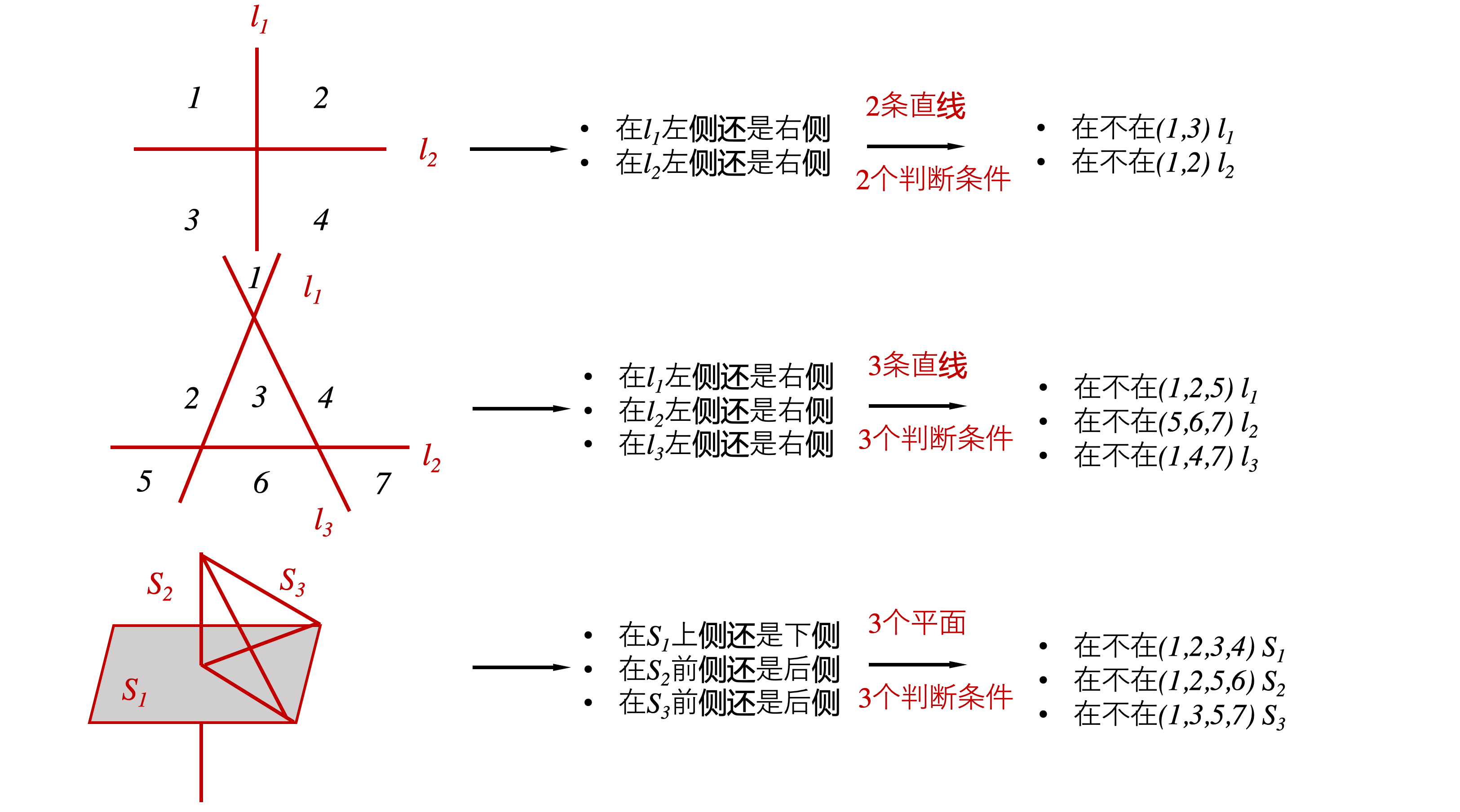
思路二:
从手机状态角度来看,每个手机只有(有人看过)(没人看过)两种状态,通过手机间状态的组合,能表示出 $2^n$ 种状态。
1
在一个 0/1 二分类任务中: 我们训练了一个神经网络,对于每个样本点,其输出为样本是 1 类的概率; 通常,我们会设置一个 threshold,如果预测的概率大于此值,则分类为 1 类,反之为 0 类; 假设,当 threshold=0.5 时,预测结果的 precision 和 recall 为 0.8,0.8 此时,把 threshold 调高到 0.6 则最有可能的 P,R 分为为 A 0.9 0.9 B 0.9 0.7 C 0.7 0.9 D 0.7 0.7
二分类中 Precision, recall 均指正类的 P R
\begin{array}{l|c|c} \hline \textbf{ 真实-预测 } & \textbf{1} & \textbf{0} \\ \hline 1 & \text{TP} & \text{FN} \\ 0 & \text{FP} & \text{TN} \\ \end{array}
其中,
\begin{equation} p=\frac{TP}{TP+FP} \end{equation}\begin{equation} r=\frac{TP}{TP+FN} \end{equation}
当提高 Threshold 时,预测为 1 的样本数量减少
即 TP + FP 减少, FN + TN 数量增大
- 若 TP 数量不变,则 P 变大,r 不变或者减少
- 若 TP 数量减少,则
$p=\frac{TP}{TP+FP}=1-\frac{1}{TP/FP+1}$- 可以看出 p 与
$\frac{TP}{FP}$成正相关 - 当
$\frac{TP}{FP}$增大时,p 增大 - 反之,p 减小
- 此情况下 recall 均会减小
- 可以看出 p 与
初始时,$\frac{TP}{FP}=4$,当 threshold 变大时 1 类中正确的比例应该增大,故 0.9 0.7 更有可能
2
下列函数不是凸函数的是 A
$f(z)=\max (0,1-z)$B$f(z)=z^{3}$C$f(z)=\exp (-z)$D$f(z)=\log (1+\exp (-z))$
凸函数直观的感觉就是图像往下凸的
可以用二阶导大于 0,若不可导,则判断对于任意 x,y 是否满足$f(y) \geqslant f(x)+f^{\prime}(x)(y-x)$
3
GoogleNet 中
$1\times 1$卷积的作用 A 降维 B 减少参数 C 跨通道通信 D 以上三项都对
- One by One [ 1 x 1 ] Convolution - counter-intuitively useful
- What does 1x1 convolution mean in a neural network?
- 卷积神经网络中用 1*1 卷积有什么作用或者好处呢?
4
考虑一个 0/1 二分类模型,模型的参数为实数 w,b,输入为一个实数 X,输出 Y 的表达式为
$Y=\left\{\begin{array}{ll}{1,} & {\text { if } w * X+b>0} \\ {0,} & {\text { otherwise }}\end{array}\right.$假设我们的训练集中包含 N 个样本点,(无重复点) 以及样本点对应的标签 请问当 N 最大是多少时,不论训练集 X 和 Y 的取值如何,都能得到一个训练误差为 0 的模型 A 2 B 3 C 4 D 大于 4
相当于,问最多几个点能由一根线分隔开
显然四个点就不行了
5
下面是一段 py code,当 n 很大很大的时候,输出值会趋近于何值? A 1334323 / 1679616 B 1334324 / 1679616 C 1334325 / 1679616 D 1334326 / 1679616
import random
def foo(n):
x = 6
y = 1000000
count = 0
for i in range(n):
cur = y
print(i)
while cur > 0:
i = random.randint(0, x - 1)
if i > cur % x:
break
elif i < cur % x:
count += 1
break
cur = cur // x
return count /n
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
这道题,稍微有点意思,看代码,大概是做一个随机采样的工作
- 当采样值 > cur % 6,停止采样
- 当采样值 < cur % 6, count += 1 停止采样
- 当采样值 == cur % 6, cur = cur // 6,继续采样
可以看到随着 n 的次数的增大,越接近采样的概率期望值
- 1000000 % 6 = 4
- 166666 % 6 = 4
- 27777 % 6 = 3
- 4629 % 6 = 3 。。。
我们可以看到取余值不是一个定值,于是写个循环来计算一下期望
def mean():
begin = 1000000
cur = begin
count = 0
num = 0.0
while cur > 0:
temp = cur % 6
num += ((temp) / 6) * pow((1/6), count)
count += 1
cur = cur // 6
return num
2
3
4
5
6
7
8
9
10
11
6
如果你用计算机进行一项计算任务 T,其中子任务 T(a)在的计算机内部模块 A 的处理时间为整个任务处理时间的 40% 现假设模块 A 的速度提升为原来的 10 倍,其他不变,这整个计算任务回提速为原来的_ 倍(保留三位小数)
额,送分题
7
假设你训练了一个线性回归模型,
$y=w_1 \times x_1+w_2\times x_2+w_3 \times x_3+b$其中$X=[x1,x2,x3]$为输入,$[w1,w2,w3,b]$为模型的参数 已知,当$X=[1,2,3]$输出 1,$X=[-1,1,4]$时,输出 2 当$X=[0.6,1.8,3.2]$,输出多少
(感觉回到了高中 hhh
$W[1,2,3]+ b=1$$W[-1,1,4]+ b=2$$W[0.6, 1.8, 3.2] + b=?$
故,
\begin{equation} m[1,2,3]+n[-1, 1, 4] = k[0.6, 1.8, 3.2] \end{equation}
=>, \begin{equation}\frac{4 M+ N}{5}=W[0.6, 1.8, 3.2] + b=1.2\end{equation}
8
老版微信中,【看一看】有【朋友阅读的原创文章】功能,当一位好友阅读某文章后,该文章就会被系统匿名推荐显示在你的微信【看一看】中。如果参数逐一删除好友,直到删除好友后该推荐文章即可消失,就可推断 TA 在看该篇文章。 假设
- 你有 888 位微信好友
- 你有多部手机,每部手机对应一个微信账号,你可以任意分配组合每部手机里面的微信好友(不限数量,可重复)
- 一篇推荐的文章最多只被一位好友阅读 问; 现在你被推荐了一篇文章,在不删除好友、不进行变更好友组合的前提下,至少需要几部手机才能才能太通过便览各个手机的文章显示情况就能知道谁在看这篇文章
思路一:
转换为 d 维空间 n 刀切最多能分为多少块?
思路二:
从手机状态角度来看,每个手机只有(有人看过)(没人看过)两种状态,通过手机间状态的组合,能表示出 $2^n$ 种状态。
9
小刚用 C 语言实现了一个 print——bytes 函数,输入 x 为一个无符号的 32 位整形(4 个字节),然后将这四个字节依照在内存中的存储地址,由低到高依次输出每个字节对应的数字, 数字连续,例如 0x01, 0x0a, 0x02, 0x0b, 则输出 110211 若在小端计算机中,调用该函数输出 012345,则 x 最大值为
0 一定是低位,然后依次推
10
MNIST
$6w \times 28 \times 28$的手写字母数据集 把 4 张按$14 \times 14$剪开,打乱,让你找出这 4 张具体是啥
DataSet: 链接:https://pan.baidu.com/s/1RK1Yz1hVSnFaogRsZHZ0Eg 密码:o6ui
暴力遍历,(比较奇怪的是为啥用 jit 之后还更慢了,摊手
from numba import jit
def read_data():
data = np.load('mnist.npz')
x_train = data['x_train']
y_train = data['y_train']
crops = data['crops']
return x_train, y_train, crops
@jit
def load():
picture_list = []
for ii in x_train:
picture_list.append(ii[0:14, 0:14].copy())
picture_list.append(ii[14:28, 0:14].copy())
picture_list.append(ii[0:14, 14:28].copy())
picture_list.append(ii[14:28, 14:28].copy())
return picture_list
# @jit
def search(picture_list, corps):
result = []
for ii, jj in enumerate(picture_list):
for kk, mm in enumerate(crops):
if (jj == mm).all():
result.append((ii, kk, y_train[ii // 4]))
# print(ii, kk, y_train[ii // 4])
return result
def judge():
start = time.time()
x_train, y_train, crops = read_data()
picture_list = load()
result = search(picture_list, corps)
result_id = [ii[0] for ii in result]
result_num_pre = [ii for ii in result_id if ii +
1 in result_id and (ii + 2 in result_id) and (ii + 3 in result_id)]
result_num = [y_train[ii//4] for ii in result_num_pre]
print(result_num)
print('{:.2f}s'.format(time.time() - start))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42