直男届的杀手-『小冰』架构解析
19 年的 第一篇 水文 献给 瞎折腾许久的
Dialogue领域考试周 还 这么闲 怕是要凉了 下次 Update 应该是月底了
本文 总结自 The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. [Li Zhou et al. 18.12]
这篇论文 算是 很好的 解读了 XiaoIce 的体系架构 包括同步一下 最近几年的 MSRA 小冰组 的研究成果
值得一提的是 大名鼎鼎的 沈向阳 博士 是 这篇文章的四作
之前 是 从机器之心 中 了解 到 这篇 文章的
但 相对于 长达 26 页的 paper 那篇文章 似乎 没有 focus on key
(古月言兌 我没有 造轮子 )
Current XiaoIce

已经9102年了 XiaoIce 也已经迭代了 6 个版本 拥有 6.6 亿用户 超过 300 亿由用户发送的 对话 数据
现在的小冰 拥有超过 230 个技能 比如说 一些炫酷的功能『识别卡路里』,『失恋33天』
上图 是一个典型用户 从 第一次和小冰 对话的 生疏 到聊动漫 再到之后的倾诉情感问题
在小冰的对话 中 我们可以发现 Reply 不仅仅是是一个 陈述句
比如说 Query: 哦。 一般女生喜欢什么样的男生呀, 小冰没有只回答一个描述性的语句 还给出了一个引发话题的短句Reply: 贴心温柔的,不过谁也不知道会喜欢上谁,感情的事说不准
我们的直男朋友 多学着点 呜呜呜 🙃
至于 XiaoIce 是如何拥有这种 能力的 这就是 我们接下来 想讨论的部分
如何 评价 小冰 这种 Open Domain Social
long-termDialogue System 的性能?
当然 单次对话 轮次 Conversation-turns Per Session (CPS) 是一个很重要的 指标
第六代 XiaoIce 现在的 CPS 已经能达到 23 相较于第一代 只有 5 的 CPS 确实 已经是 质的飞跃 (当然 这里面 肯定 也有 DataSet 变大 的 作用)
小冰 设计的目的 是一个 AI Companion, 试图 设计一个 能通过 分时的图灵测试 的系统
小冰 不同于 其他的 Social Chatbot 在设计之初 就确定了 拥有自己独特的语言风格 或者称之为 '人'格
小冰 是一个 18 岁的小仙女 她可靠富有同情心亲热 又不失幽默
她还具有超高的智商和情商 (行了 直男别活了 886)
IQ: 为了达到 IQ 的目的 需要小冰具有很大的 Knowledge 储备,且能做到 Personality 的 Memory- 除此之外 还要用一些 vertical domain 的知识 比如说
美食鉴别XiaoIce 在这方便做了 230+的 Skills
- 除此之外 还要用一些 vertical domain 的知识 比如说
EQ: 一个高情商的表现 是极具同情心 能站在对话的角度 思考问题 而且能具有一定的社交技巧 能做到结合 Memory 做到个性化的回答Personality: 所有 Reply 必须符合小冰既有的风格
(我发现 我 连 做人 都不如小冰 😷)
Architecture
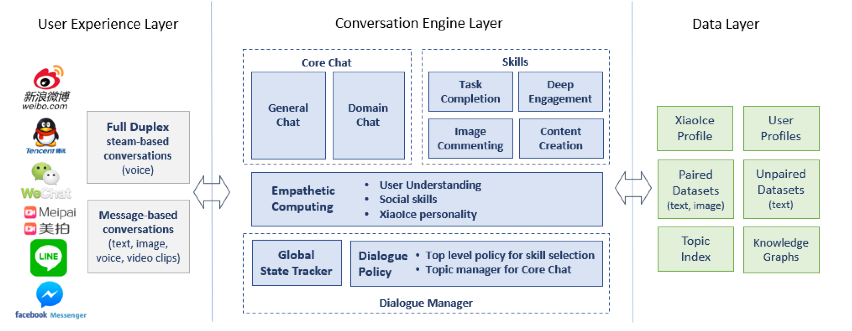
好 我们进入这篇文章要探讨的重头
从上图 我们可以看出 XiaoIce 的架构 大致上 分为 三层用户交互层对话Engine层数据层
其中用户交互层 主要是 获取 用户数据 主要分为 回合制(Message) 即使制(Full Duplex)
他们 收集到的 都是一个个Pair对 <Context, Reply> 这些 Pair 对 会 喂到后面的Conversation Engine里面进行处理
同时也会备份到 Data 层
Data 层 就是 持久化 单独而言 没有特殊的东西
但 从Data层中 我们其实也能看出一些 XiaoIce 用的技术
比如说Profile 是小冰通过 用户对话 History 等资料 解构 出 相应的画像
Paired 就是 刚才从 User 中传入的数据 而Unpaired 则是 通过一些文本信息 新闻、讲座等 Data 用于提高 生产的对话覆盖范围
Topic是主题管理索引 接下来会详细分析 Knowledge Graph是用户 Unpaired Data 的检索使用
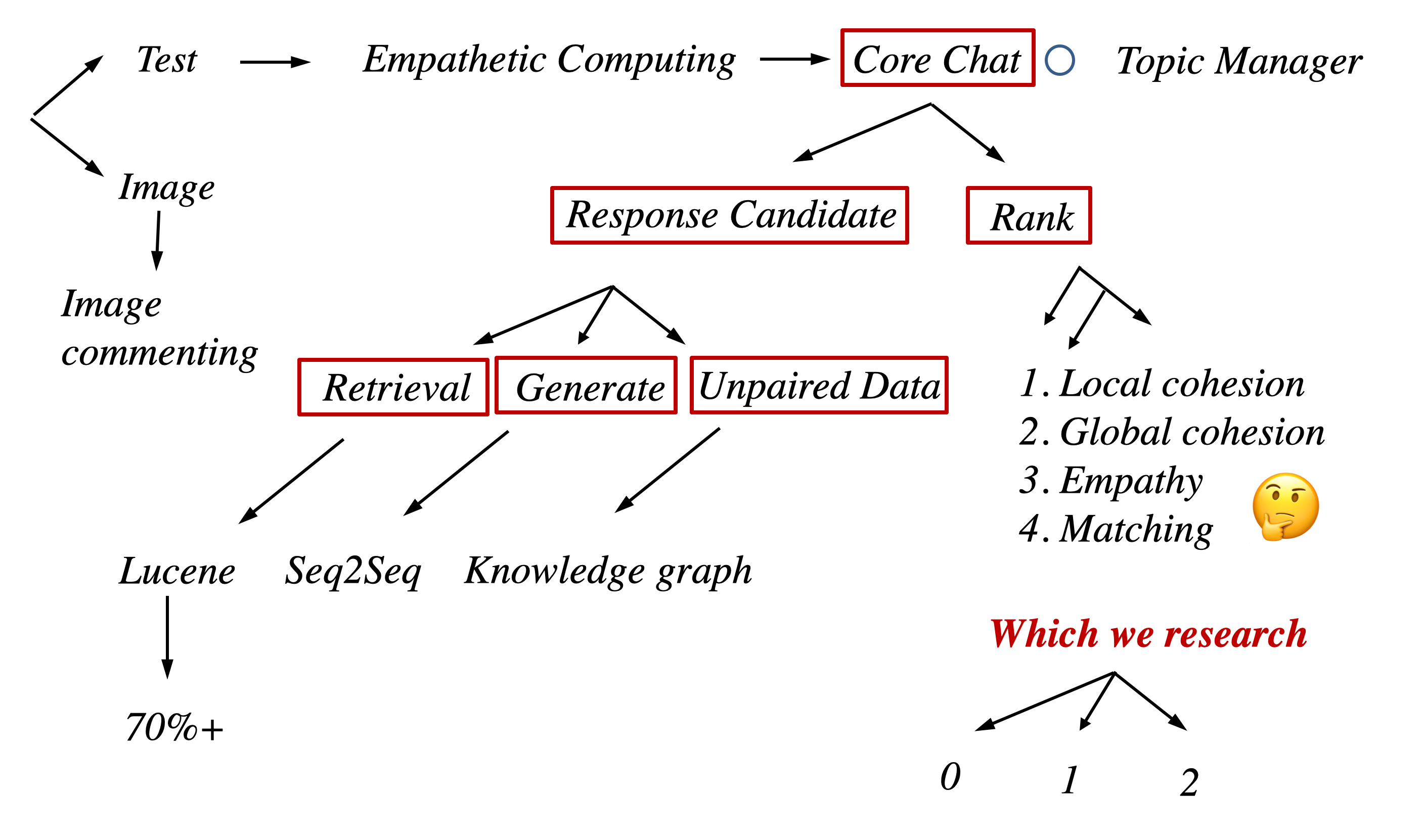
Conversation Engine 部分 是 XiaoIce Chatbot 的核心部分
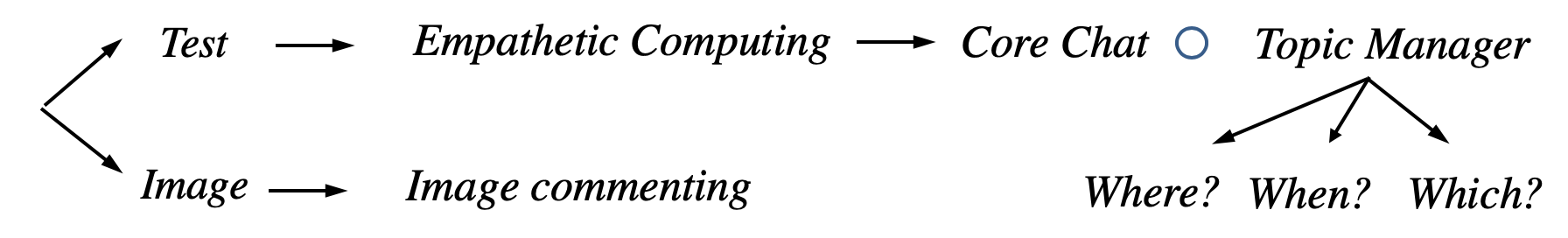
一个 Message/Full Duplex 过来 先转化为 Text 或者 Image
若为 Text 则 进行 Empathetic 同情度计算 然后把输出给到 Core Chat 由 Core Chat 决定分配给General Chat 还是 Domain Chat
然后 调用 相应的 Skill 模块 检索出 400 个候选集 最后经过 Rank 选取最符合风格 最人性化的 Reply 这样 一轮对话 就结束了
然后根据 Topic Manager 进行判断 要不要 切换主题, 切换到什么样的主题 当然 主题候选集的构建 也是 其工作之一
如果是一个 Image 进来 则对抽取 图像的 信息 并做评价
详细来说
Dialogue Manager
对话管理器 除了 记录历史对话 还包含 对话策略 管理
对话策略 管理 即管理 Skill 的终端 什么时候 触发 skill 什么时候 切换 Skill 等等
同时 Conversation 还受到Topic 的管理
在 Pre-Train 阶段 先对 Instagram 和 Douban 上的数据 得到一个 Topic Index
当触发一些 Topic 切换的 标志的时候,比如说:
- Core Chat
未能生成有效的候选集 - 生成的响应只是用户输入的
重复 - 用户输入变得
平淡, "OK", "I see", "Go on"
这时候 就 会调用 Topic 切换,切换之后的 Topic 根据以下几个指标选取:
上下文关联性新鲜度个人兴趣热度接受度
Empathetic Computing
同情度计算 算是 小冰 Chatbot 相对独特的一点
它不是 直接 把 Context 和 Reply 进行匹配 得到一个 Match Score 值
而是由 Query, Context, Reply 及情景分析 得到一个$s=(Q_c, C, e_Q, e_R)$ 向量
再由这个向量 根据 Core Chat 得到 所要选的值
Contextual Query Understanding
CQU这一步 主要 做的是 句子补全的工作
首先 拿到 Context 之后 做了 一个 命名实体标识
把所有代词 用 实体 替换, 如果句子不完整 也 补全
比如说 I hate it. 在上下文中 it 指的是 tomato 就转变为I hate tomato.

User Understand
根据 Context 对 用户的目的, 情感, 主题, 观点, 用户画像 进行分类
得到一个带有用户情绪的empathy vector $e_Q$
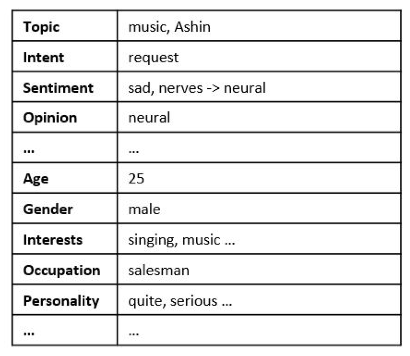
比如说 这里的 目的 是 Request, 主题 是music
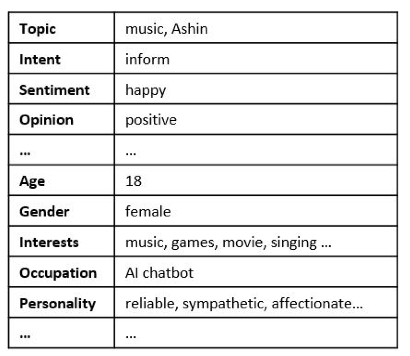
Interpersonal response generation
看名字 可能 不要好理解 刚才 我们生成的是 带有 user empathy 的 vector $e_Q$
现在 我们要生成的是 带有回答者 也就是 XiaoIce 的 Empathy 的 vector $e_R$
构造方式 同 $e_Q$ 只不过 这里的属性值是 PM 讨论出来 写死的
Core Chat
构造好 带有用户 和 小冰 情绪的 vector $s$ 之后 就到了 最关键的 语言生成环节 Core Chat
XiaoIce 在处理这个问题的时候 用了 两阶段法
先 通过 某种 方式 构造一个 Reply候选集 然后 根据 某种方式 计算得 每个 Reply 的 Score 从中选出最优的
看到这里 我想大家以前跑SMN 跑 DAM 跑检索式对话模型 的 疑问 就消失了吧
以前一直 在想 检索式 对话 检索式 对话 为啥 还会有 候选集 什么样的 条件下 会有这个候选集 🎎
终于 一切 都 顺理成章了 🙊
在构造 候选集的过程中 用到了 三种方式
Retrieval-based using Paired Data
数据来源于 小冰 从 2014 年 以来 超过 300 亿轮的 用户数据 根据每个$s=(Q_c, C, e_Q, e_R)$ 向量-Reply 构造 Index
真正使用过程中 由$Q_c$利用Lucene 进行查找 取前 400 个作为候选集
目前来看 小冰 超过 70% 的回答 来自于 之前用户的对话当中
Neural Generate
当然 单纯 靠检索 来获得数据 会漏掉一些 最近的热点 覆盖面 不会太高
这个时候 就会用生成式对话
目前一般使用Seq2Seq
在小冰的架构中 先对前面构造的 s 向量做一个SIGMOD操作$v=\sigma(W^T_Qe_Q+W^T_Re_R)$ 每一轮都喂到 Neural 中
这样保证了生成的 Response 带有 XiaoIce 的'人'格
Retrieval-based using unPaired Data
为了提高 小冰的 IQ(好 碾压 我们)
除了 上面的 一些 基本 操作之外 还 从讲座、新闻 等unPaired的 Text 中 抽取一些候选集
但因为 不是 Paired 的 在构造的时候 为了 可扩展性
除了$Q_c$之外 还利用 Knowledge Graph 搜取相近的 Topic 一起 喂入
然后一样的构造 索引 一样的用Lucene得到内容
Rank
这其实就是多轮检索式对话的内容了
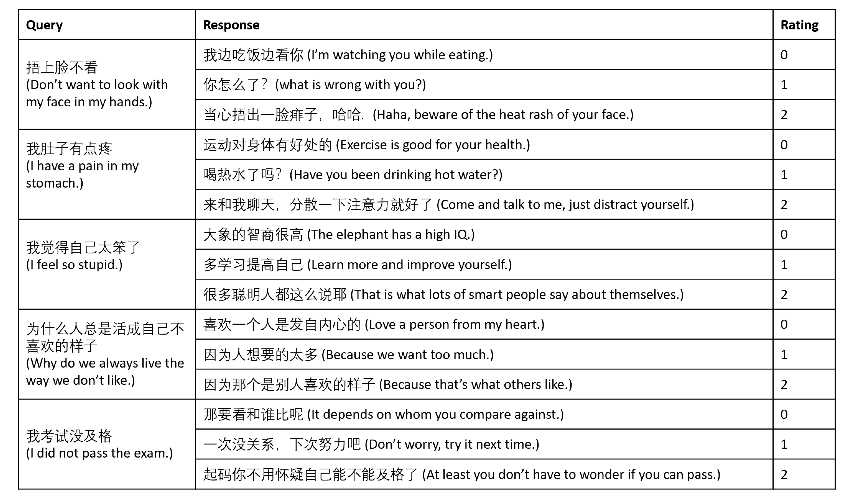
当然 最简单的想法 就是 算算TF-IDF 但 这样 对于长句而言 效果不会很好
就有DSSM(那个 微软 发的 开山之作) 基于交互式的SMNDAM 甚至Bert
当然 这里进行 Rank 的时候 还必须 考虑到 XiaoIce 的人设
这打分 扎心 了 直男 永远只能得 0 分 😤
Skills
当然 除了 最基本的 Conversation 之外 XiaoIce 还有很多技能
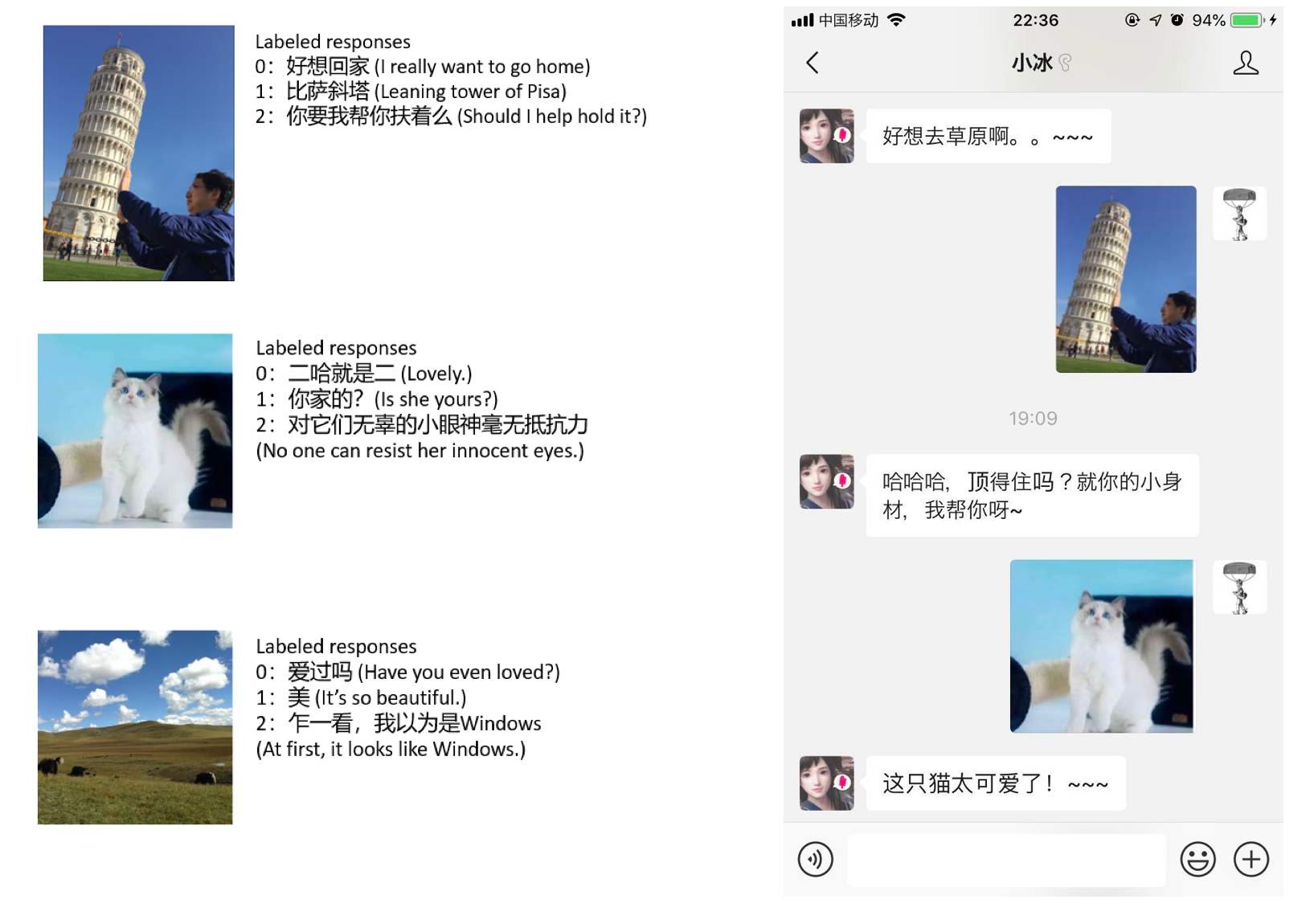
比如说 你可以 发图片给他
Image 的回复 是 通过 Image-Comment 数据集 训练出来的
把 Facebook Weibo 这种社交网络中的 图片 及其 评论数据 爬取下来 通过 CNN 进行抽象 获取一个 Image 的 vector
然后 根据这个 vector 和 CNN 进行索引
同样利用两阶段法 先构造候选集 再进行 Rank
还能 识别 食物的卡路里 我还 特意试验了 一次 惊了

除了这些之外 小冰 还会 创作 基本套路 和 前面的基本一致
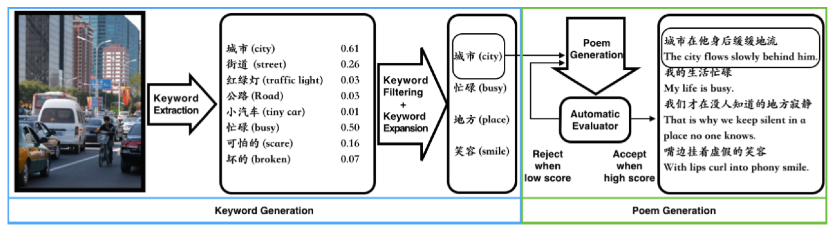
所以 惭愧的我 低下了头 摊手 🙉
以后 有人问你 工资卡 给她管的 时候 别再说 你要留后路了
Reference
. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. [Li Zhou et al. 18.12]